Zip Bombs Against Aggressive AI Crawlers
Website owners are fighting back against relentless AI crawlers that ignore robots.txt and generate thousands of requests per minute, deploying zip bombs and proof-of-work challenges as defensive weapons.
Website owners are facing a growing crisis. AI crawlers — bots that scrape the web to feed training data into large language models — are hammering servers with unprecedented ferocity. According to a Fastly analytics report, these crawlers sometimes generate up to 39,000 requests per minute against a single site. In 2025, the load from scrapers increased by 87%, driven primarily by RAG (Retrieval-Augmented Generation) scrapers.
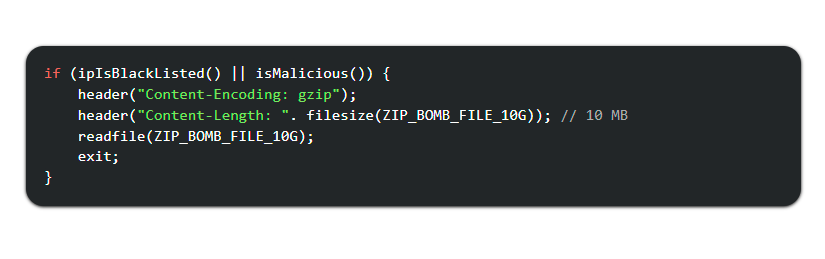
AI crawlers generate approximately 80% of all AI bot traffic on the internet. The scale of the problem is staggering. ClaudeBot from Anthropic sent one million requests in a single day to iFixit.com. The same bot fired 3.5 million requests at Freelancer.com in just four hours. These are not isolated incidents — they represent the new normal for any website with meaningful content.
Traditional Defenses
Webmasters have several conventional tools at their disposal:
- Rate limiting: Restricting the number of requests a single IP address can make per time period
- CAPTCHA systems: Requiring human verification before serving content
- User-agent filtering: Blocking requests from known bot user-agent strings
- IP address blocking: Maintaining blocklists of known bot IP ranges
But these traditional methods have significant limitations. AI companies rotate IP addresses, change user-agent strings, and deploy distributed crawling infrastructure that makes simple blocking ineffective. Some crawlers blatantly ignore robots.txt directives — the gentlemen's agreement that has governed web crawling for decades.
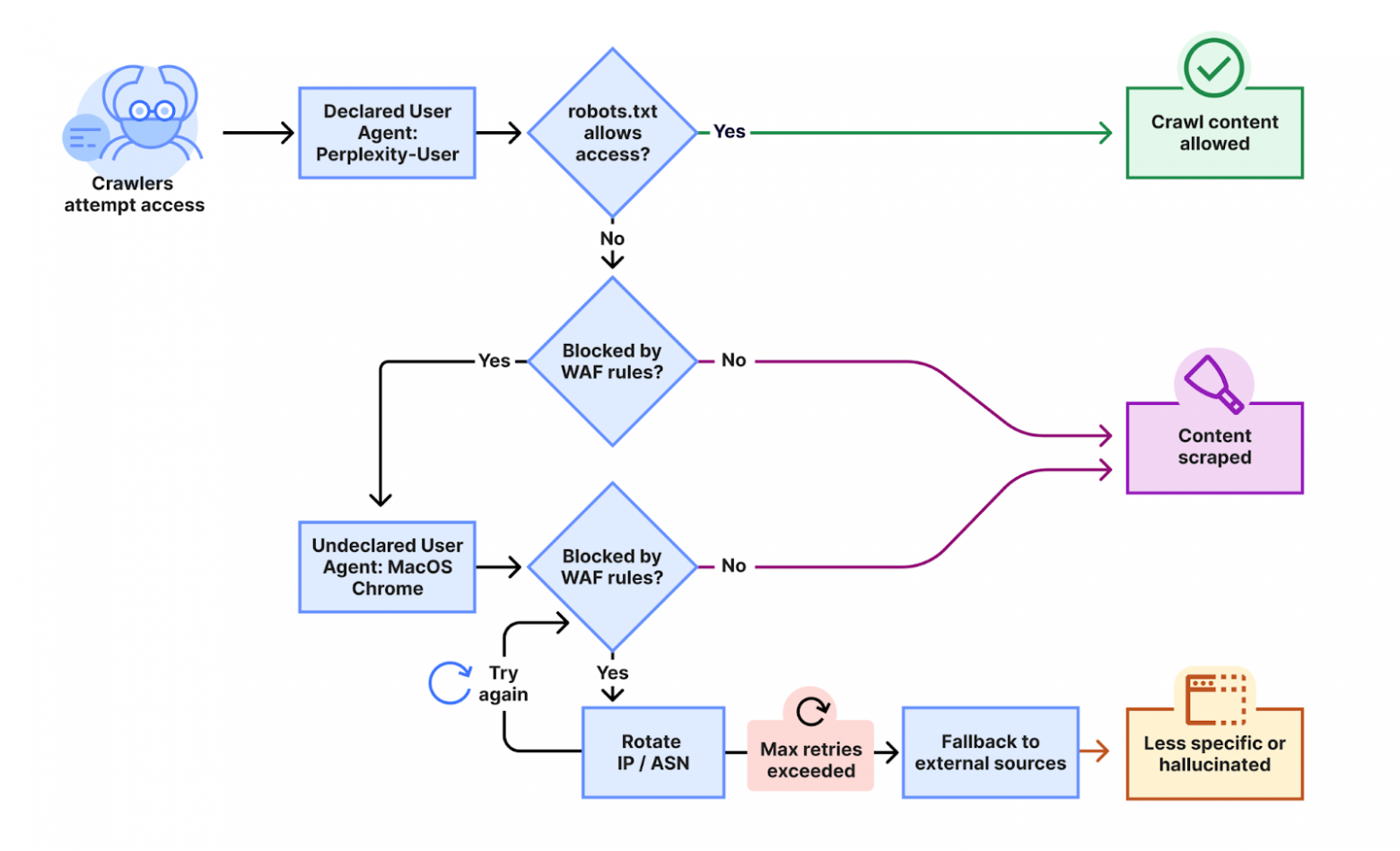
Anubis: Proof-of-Work Defense
A more creative approach is Anubis — an open-source system that requires clients to solve a SHA-256 computational challenge before accessing content. Essentially, it's a proof-of-work system similar to what Bitcoin uses. Every visitor must expend computational resources to prove they're serious about accessing the content.
The project has gained significant traction, with 13,000 stars on GitHub. However, critics point out that for well-funded AI companies with massive data center resources, the computational cost of solving these challenges is "insignificant" — easily absorbed as a minor operating expense. The approach mainly inconveniences legitimate users with slower devices.
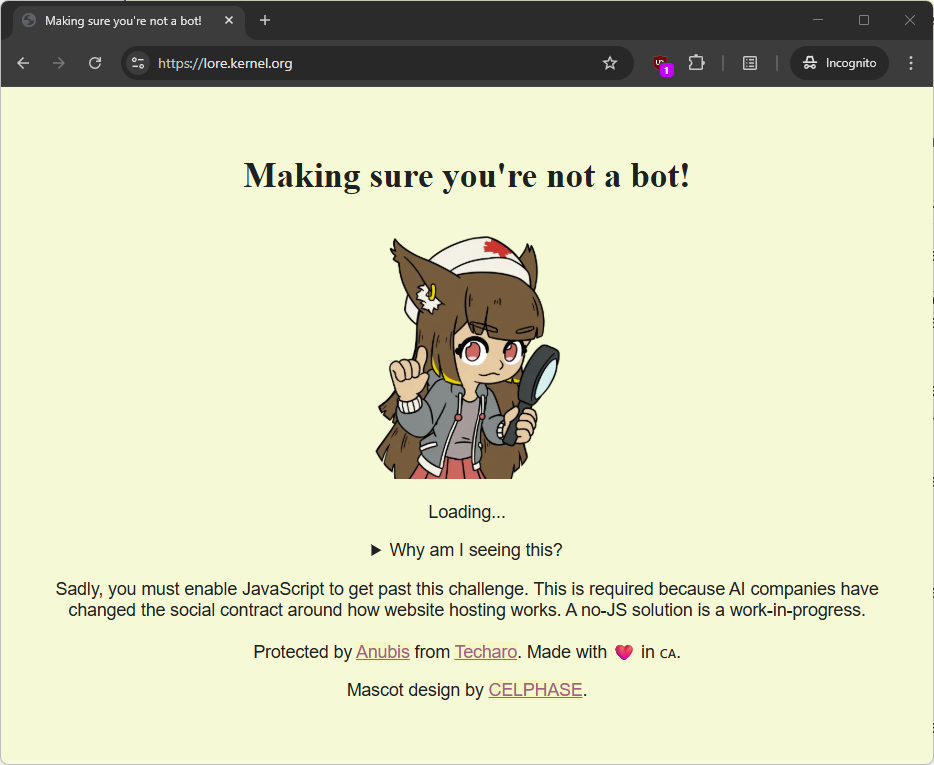
The Nuclear Option: Zip Bombs
This is where things get interesting. Some webmasters have turned to a more aggressive defense: zip bombs. The concept exploits the way compression works. A zip archive can achieve extraordinary compression ratios on repetitive data. A 10 MB archive can decompress to 10 GB of data — a compression ratio of 1000:1.
When an AI crawler requests a page, the server detects the bot (via user-agent string, behavioral patterns, or other fingerprinting methods) and serves it a gzip-compressed response containing a zip bomb. The crawler's system attempts to decompress the response, and its memory fills up with gigabytes of useless data, potentially crashing the process or the entire server.
The beauty of this approach is its selectivity. Pages containing zip bombs are hidden from regular search engines (which respect robots.txt) and from normal browsers like Chrome and Firefox. They're served exclusively to identified AI crawlers. Legitimate visitors never see them.
The Scale of the Damage
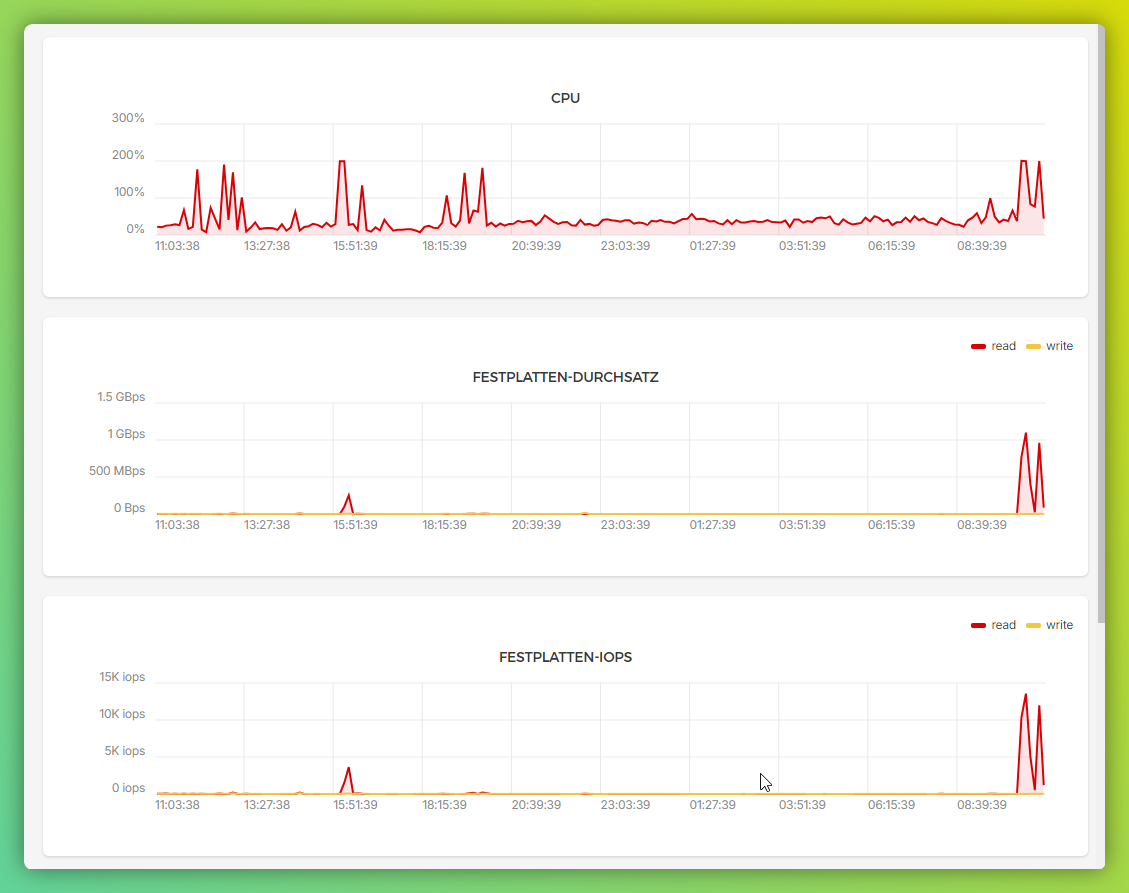
The financial and technical impact of aggressive crawling is very real. One webmaster documented that GPTBot from OpenAI consumed 30 TB of traffic on his hosting plan in a single month, despite the total size of all files on the site being just 600 MB. The bot was requesting the same pages repeatedly, generating astronomical bandwidth costs.
During crawler visits, server CPU load increases several-fold. For small and medium-sized websites on shared hosting or modest VPS plans, this can mean degraded performance for real users, or even complete service outages. Some site owners have received unexpected hosting bills in the thousands of dollars.
The Ethical Dilemma
Zip bombs are, by any measure, a destructive tool. They're designed to cause harm to the systems that trigger them. Using them raises legitimate ethical concerns — after all, two wrongs don't necessarily make a right.
Yet webmasters who deploy them argue that the ethical calculus is clear. When bots ignore robots.txt, consume enormous bandwidth, degrade service for real users, and generate crippling hosting costs — all while the AI companies profiting from the scraped data offer no compensation — the moral high ground becomes harder to define.
The defenders point out that they're not attacking anyone proactively. The zip bombs sit passively on their own servers, triggered only by bots that have already violated the site's stated access policies. It's more akin to a booby trap on private property than an offensive weapon.
The situation highlights a fundamental gap in internet governance. The robots.txt standard is voluntary and unenforceable. There's no legal framework that effectively prevents unauthorized scraping at scale. Until regulation catches up with technology, webmasters are left to defend their resources with whatever tools they can improvise.
Whether zip bombs represent a legitimate defense or a dangerous escalation depends largely on which side of the crawling equation you sit on. What's clear is that the current situation — where AI companies can freely harvest the web's content while site owners bear the infrastructure costs — is unsustainable. Something will have to give.
FAQ
What is this article about in one sentence?
This article explains the core idea in practical terms and focuses on what you can apply in real work.
Who is this article for?
It is written for engineers, technical leaders, and curious readers who want a clear, implementation-focused explanation.
What should I read next?
Use the related articles below to continue with closely connected topics and concrete examples.





