How We Loaded a Petabyte of Data into PostgreSQL Around New Year's and What Came of It
A team at Postgres Professional embarked on an ambitious experiment to load approximately one petabyte of data into PostgreSQL using the distributed Shardman system across seven physical servers, overcoming hardware failures, RAID issues, and filesystem bugs along the way.
This is the story of an ambitious experiment: loading approximately one petabyte of data into PostgreSQL. This project was carried out between December 2024 and January 2025 using Shardman, a distributed PostgreSQL-based system developed by Postgres Professional.

How It All Started
The idea was born on December 10 during a casual kitchen conversation at the office, but it quickly evolved into a serious engineering challenge. The deadline for delivering results was January 20.
The Hardware Challenge
Finding adequate infrastructure proved surprisingly difficult. Cloud providers couldn't guarantee a single petabyte of contiguous storage, and traditional data center leases were insufficient. Eventually, we secured seven physical servers from a hosting provider, each equipped with 10 x 15TB NVMe drives configured in RAID 0 arrays — roughly 140TB per server, giving us nearly one petabyte of total raw capacity.
Choosing the Benchmark
We chose YCSB (Yahoo! Cloud Serving Benchmark), specifically the Go implementation by PingCAP. The design was straightforward: a single table, hash-partitioned across seven nodes, with ten varchar columns of random data — approximately 1,100 bytes per row. To fill a petabyte, we'd need roughly one trillion rows.
First Attempt and Hash Collisions (December 10)
Early testing immediately revealed hash collision issues. The original sequential key generation created duplicate keys across threads, causing deadlocks during parallel insertion:
for (long seq = 0; seq < X; seq++) {
ycbs_key = 'user' + fnv1a(seq)
...
}The data generator simply stalled — threads collided on the same hash values and blocked each other.
Rewriting the Loader (December 20)
We rewrote the loader in Java with several key improvements: batch processing (100 rows per transaction), direct shard-aware distribution, and built-in progress monitoring. Performance jumped to approximately 150GB per five minutes on test virtual machines.
Deploying Infrastructure (December 27)
All seven servers received Debian 12, RAID 0 configurations across their NVMe drives, and the Shardman distributed database setup. Initial results were promising: roughly 150GB per ten minutes per node, though server six already showed some anomalous performance variations.
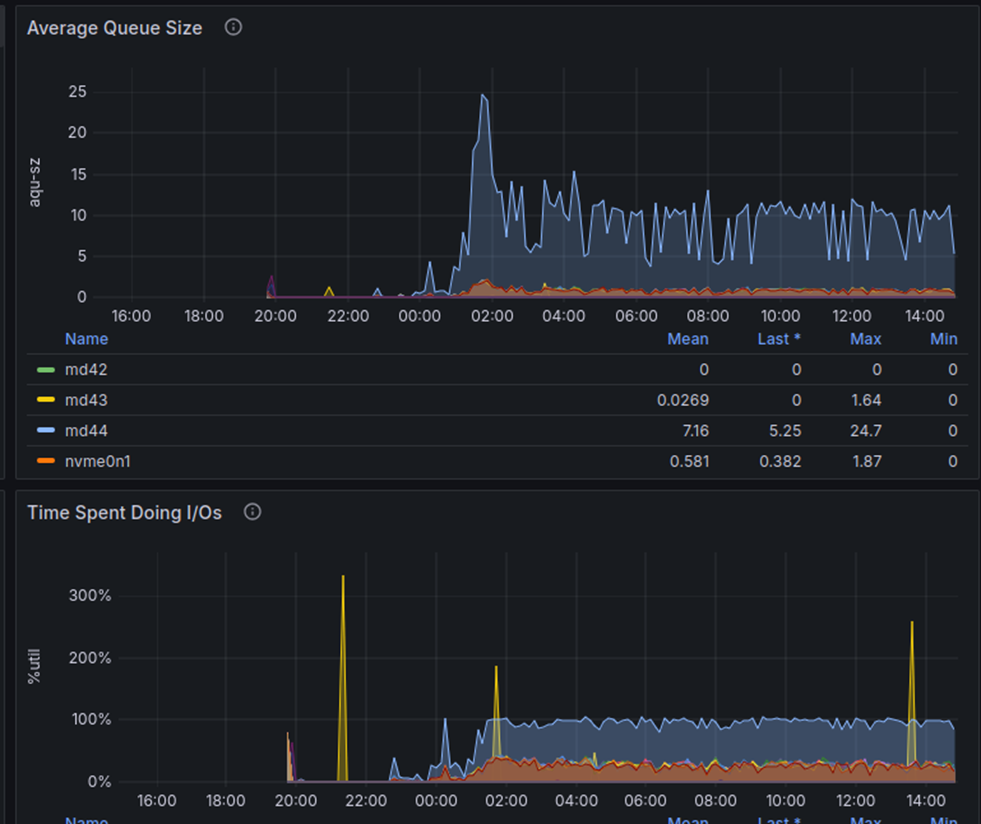
Hardware Nightmares (December 28)
Servers 3 and 6 exhibited severely degraded I/O performance — 5ms write latency versus 0.15ms on the healthy nodes. That's a 30x difference. Technical support identified potential defective drives within the software RAID arrays.
Our workaround was to decompose the RAID arrays on the problematic nodes and create separate tablespaces across individual disk drives, distributing data partitions one-by-one across the disks.
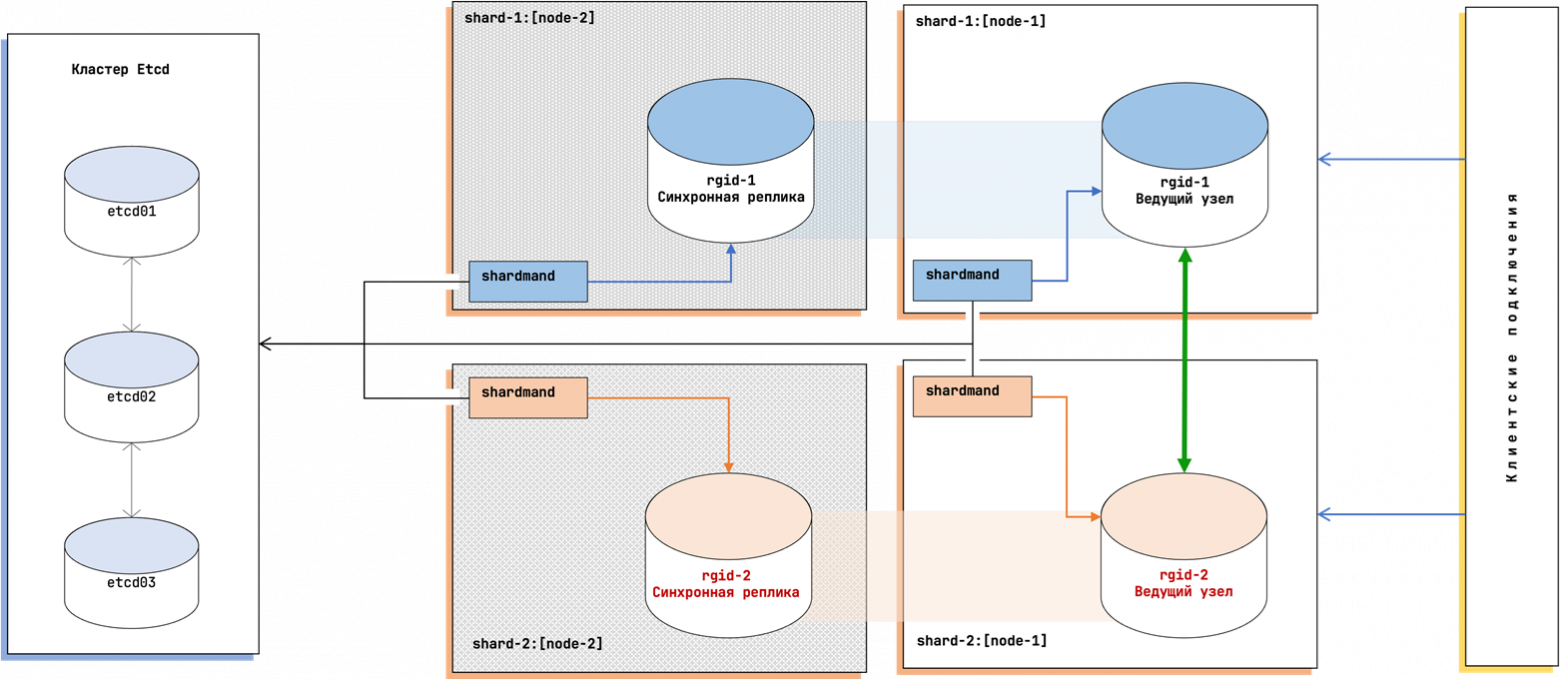
Shardman's Tablespace Constraints
Here we hit another wall. Shardman didn't support local tablespaces:
postgres=# CREATE TABLESPACE u02_01 LOCATION '/u02_01';
ERROR: local tablespaces are not supported
HINT: use "global" option to create global tablespaceWe worked around this by disabling schema synchronization and manually creating directory structures matching Shardman's expected naming conventions:
set shardman.sync_schema = off;
mkdir /u02_01/3
mkdir /u02_02/3
CREATE TABLESPACE u02_02 LOCATION '/u02_02/{rgid}';
CREATE TABLESPACE u02_03 LOCATION '/u02_03/{rgid}';Then we moved partitions across tablespaces:
ALTER TABLE usertable_2 SET TABLESPACE u02_01;
ALTER TABLE usertable_9 SET TABLESPACE u02_02;
ALTER TABLE usertable_16 SET TABLESPACE u02_03;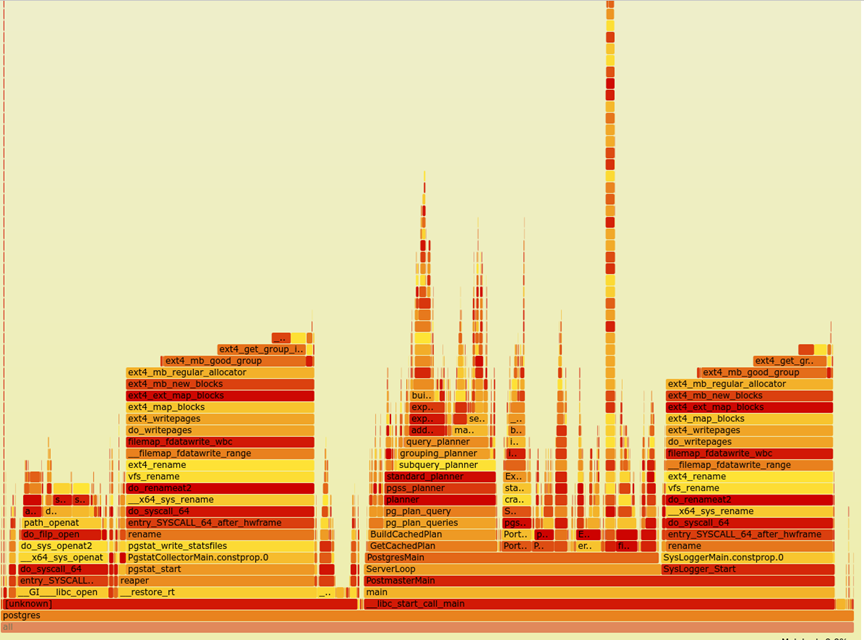
Memory Errors (January 9)
The RAS daemon started firing alerts — correctable memory errors were detected across nearly all nodes except server seven. Support staff replaced the faulty memory modules, and operations resumed after several hours of downtime.
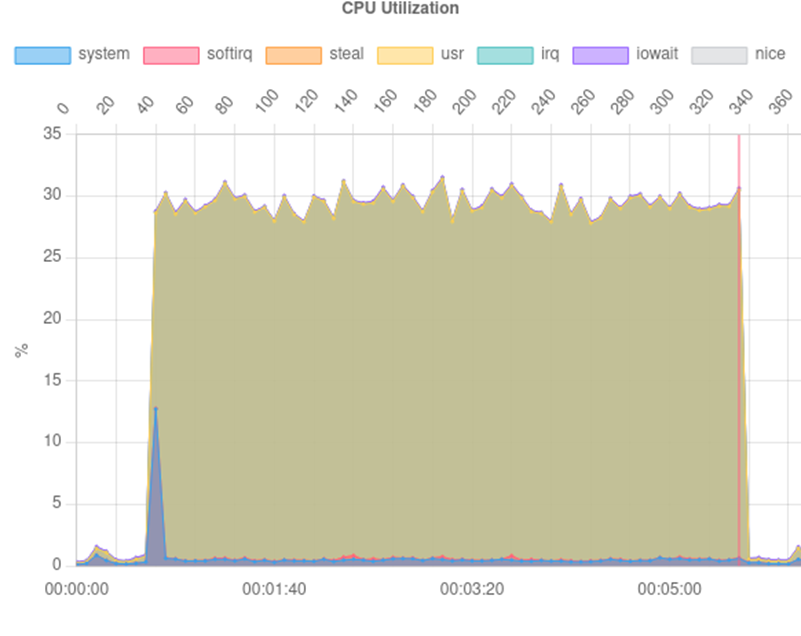
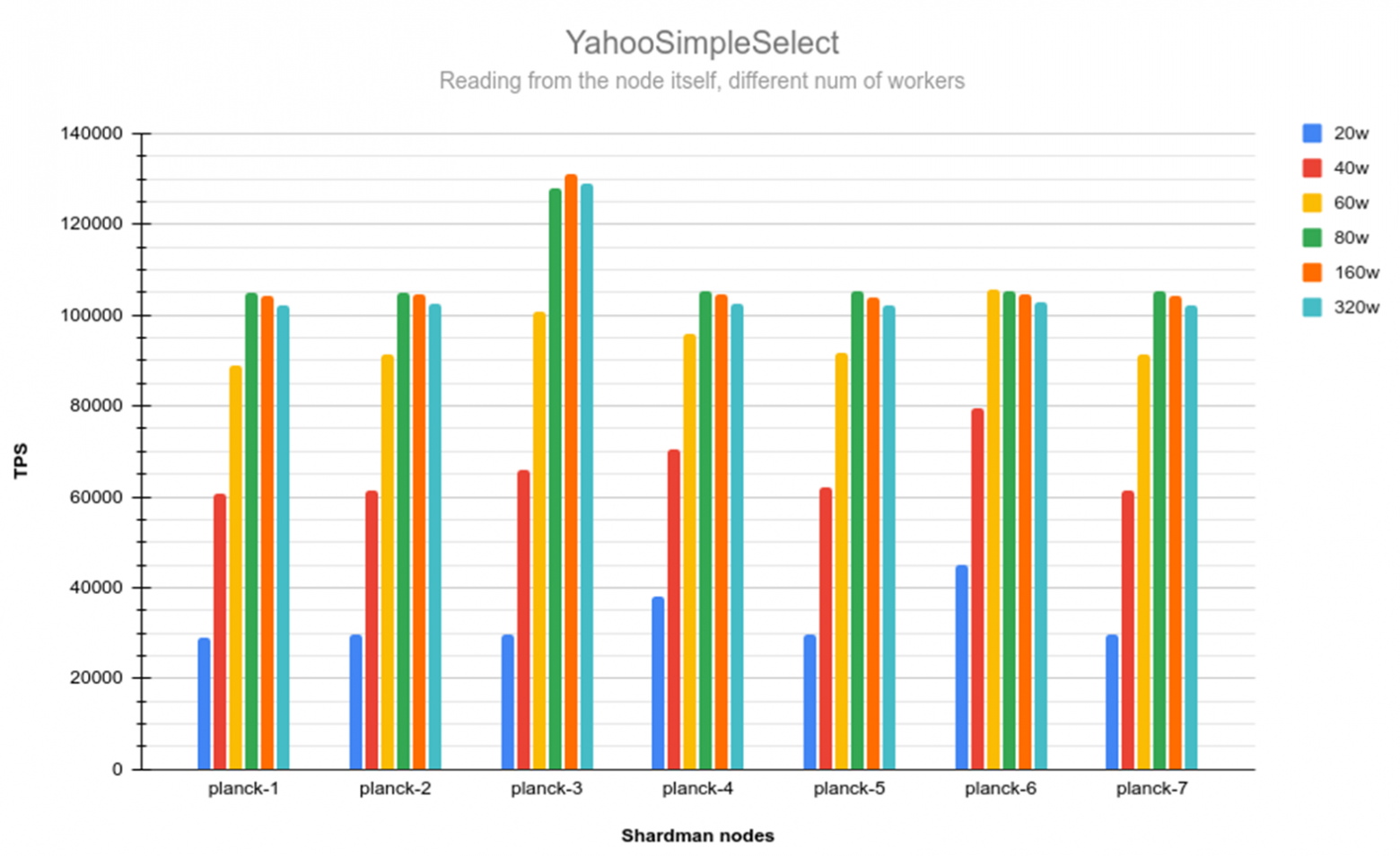
Performance Testing (January 10)
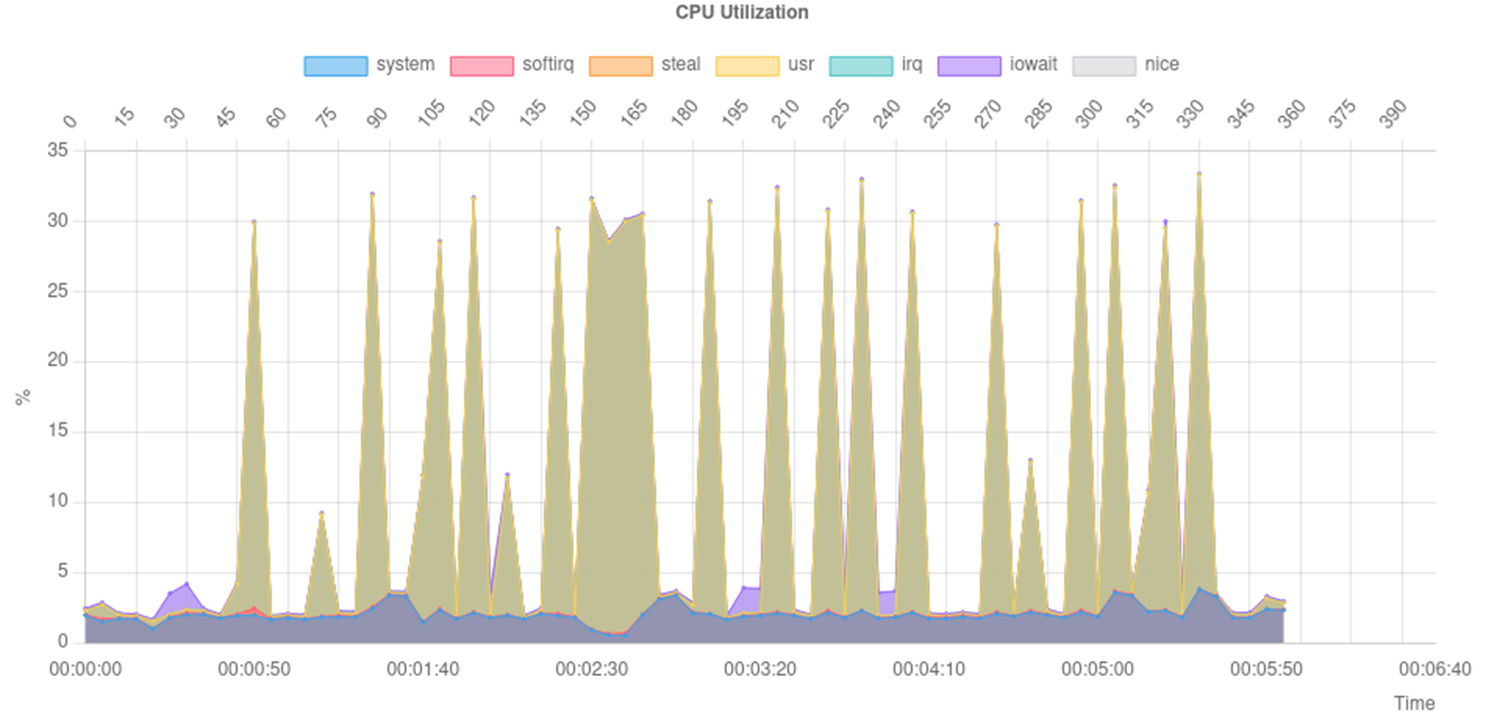
We ran YahooSimpleSelect tests and produced a performance matrix with 20 workers. The diagonal elements (local node to local data) showed peak performance. Ironically, the previously problematic servers 3 and 6 demonstrated the highest throughput: 23,673 TPS and 37,807 TPS respectively. Server 7 showed anomalously poor results at just 1,663 TPS.
The ext4 Filesystem Bug
Performance profiling with perf and FlameGraph revealed an ext4_mb_good_group bottleneck on server seven's RAID configuration. The culprit? The ext4 stripe parameter was set to 1280 instead of the default 0, causing severe CPU contention in the block allocator. Remounting the filesystem with stripe=0 immediately resolved the issue.
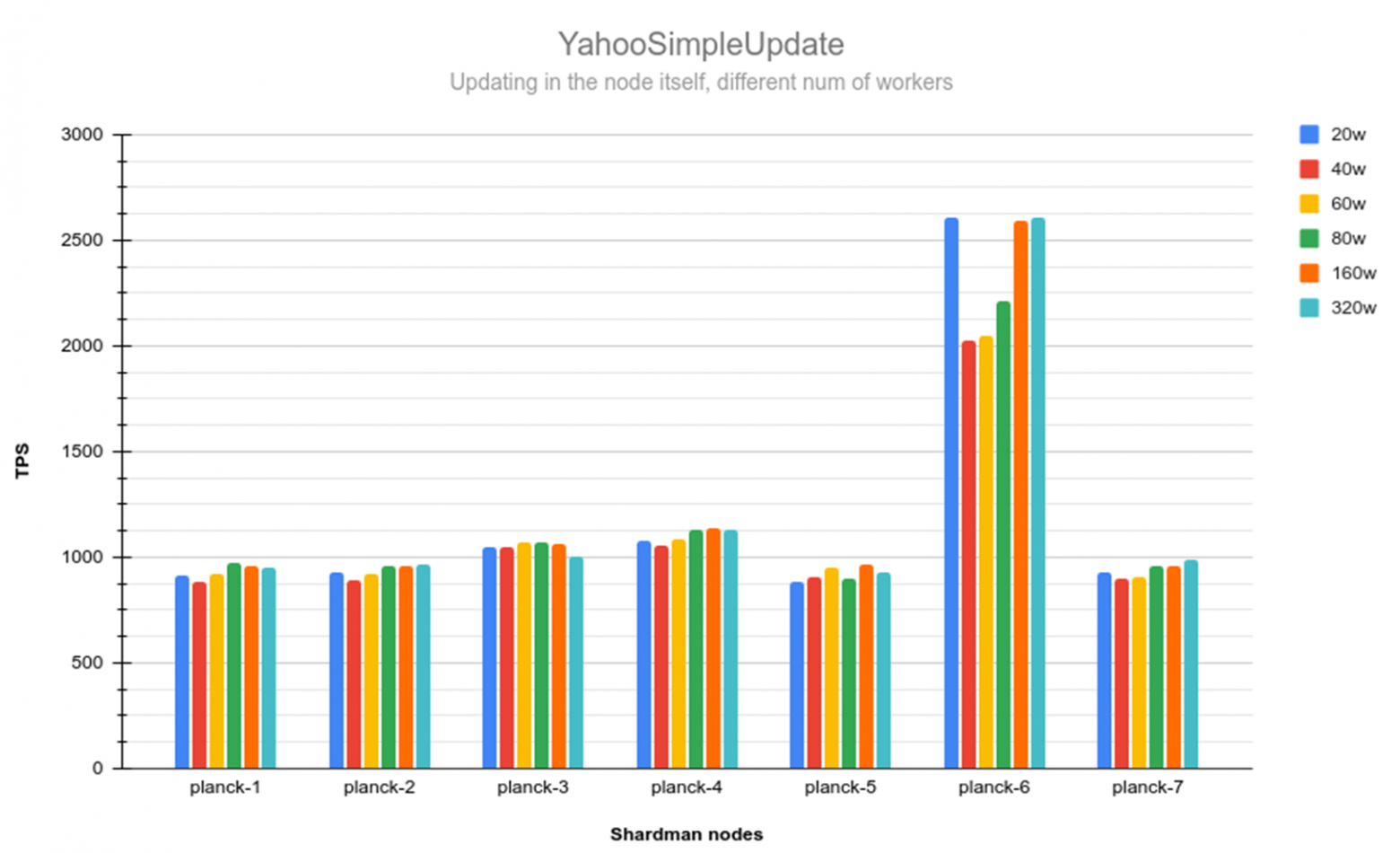
Data Loading Complete (January 15)
The final dataset reached 863 terabytes across all seven nodes, representing approximately 800 billion rows. The distribution was: planck-1 (126TB), planck-2 (107TB), planck-3 (107TB), planck-4 (126TB), planck-5 (126TB), planck-6 (126TB), planck-7 (126TB). We fell short of the full petabyte goal only because of disk capacity limits, not software constraints.
The Autovacuum Battle
Post-load, autovacuum processes became a major bottleneck. Wraparound maintenance consumed enormous amounts of time, with WAL write operations becoming the primary constraint. Our solution was drastic: disable VacuumDelay and temporarily mount the WAL directory on tmpfs. This brought the total autovacuum completion time down to about 20 hours.
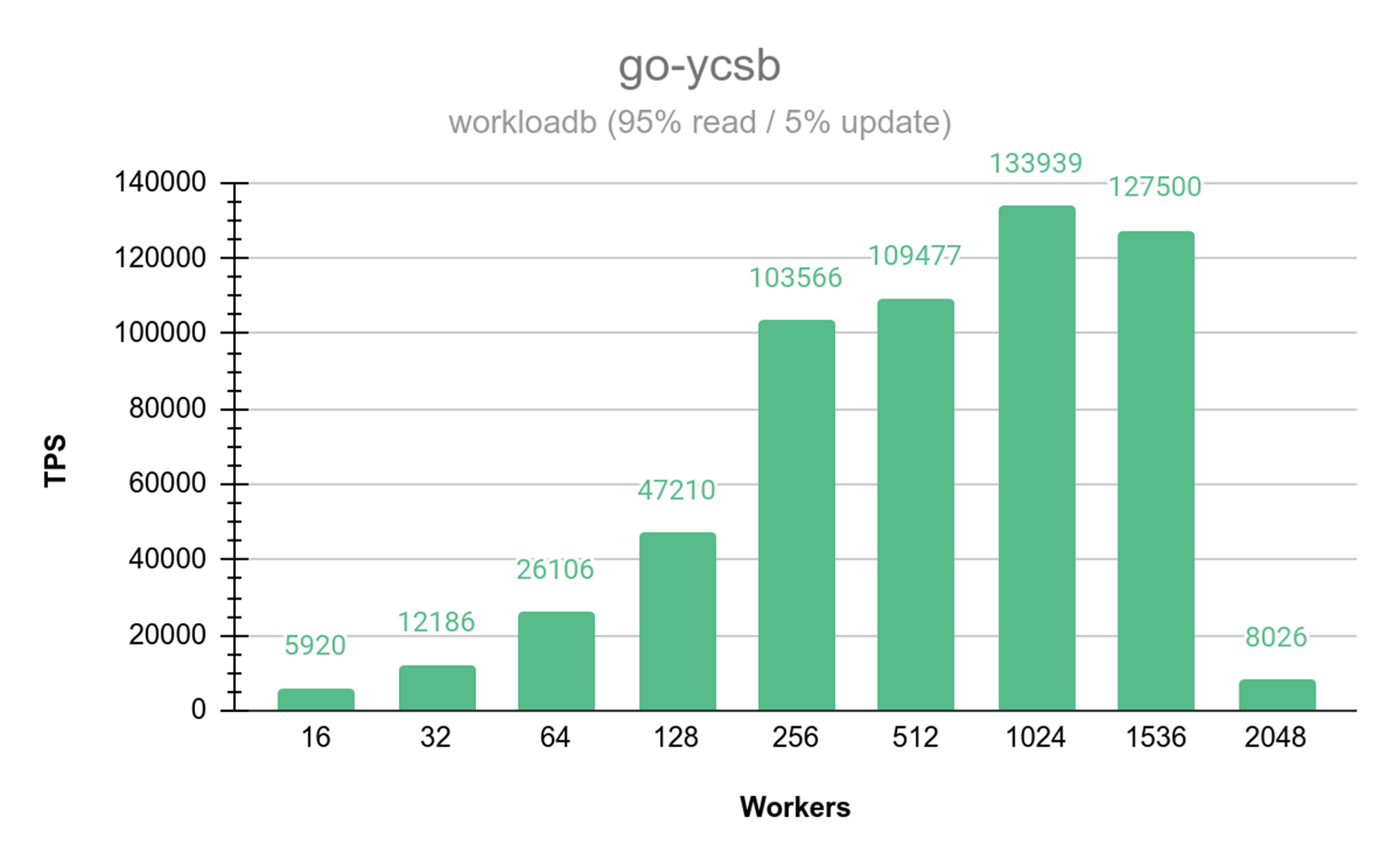
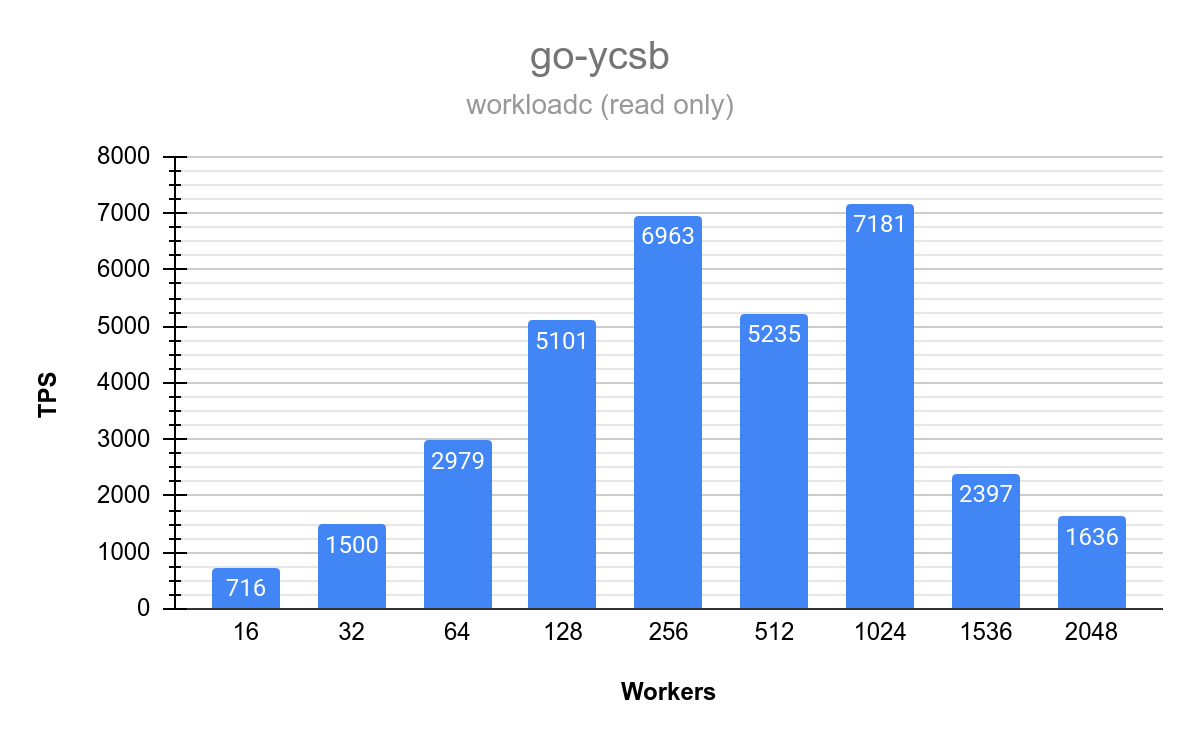
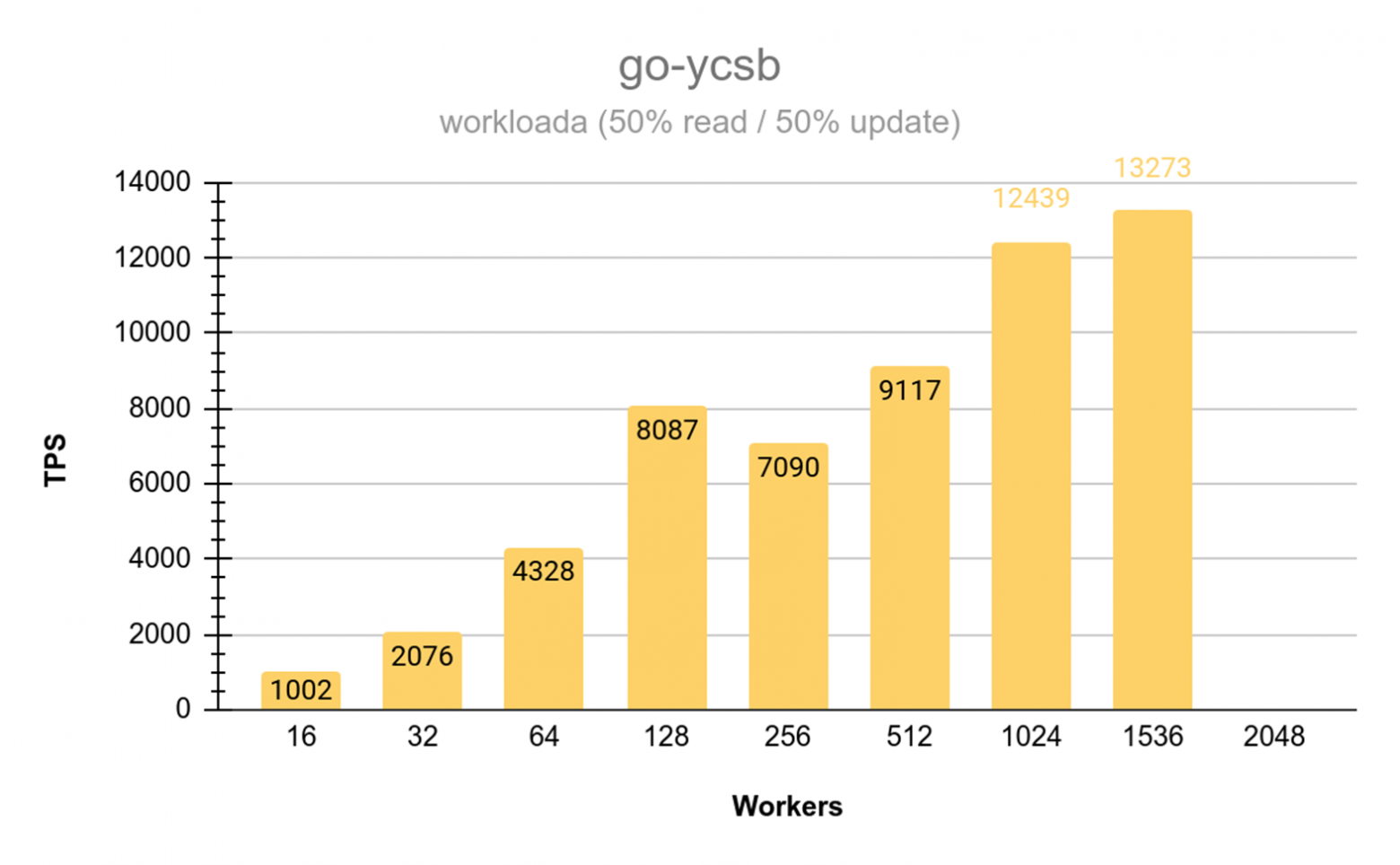
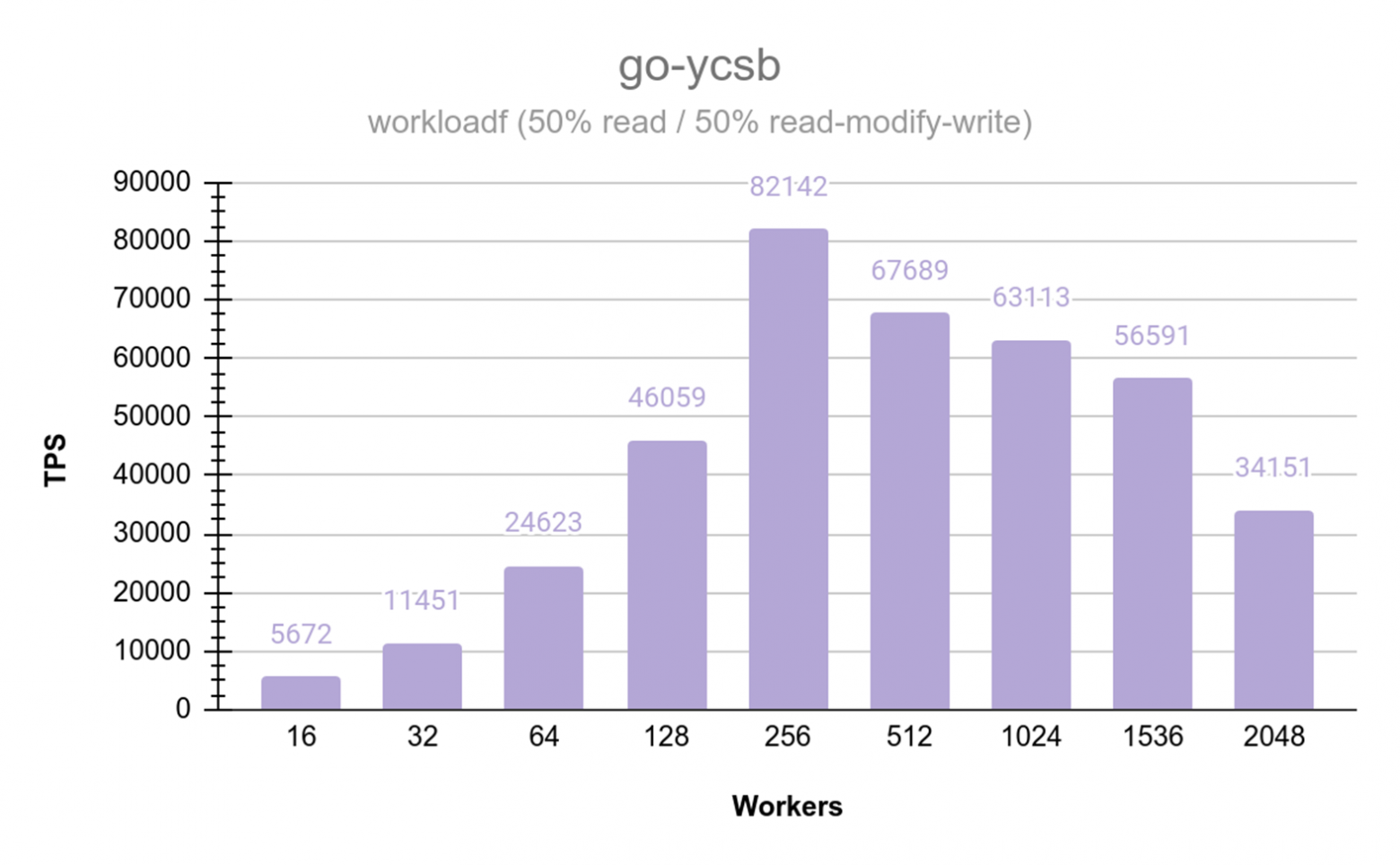
Final Performance Benchmarks (January 17)
Go-YCSB testing across varying thread counts (up to 1,500 workers) demonstrated approximately linear scaling on the 16-core Intel Silver processors. Read performance peaked at up to 37,807 TPS on optimal node configurations. Mixed read/write operations at a 50/50 ratio showed some degradation that will require further analysis.
Lessons Learned
This experiment taught us several key lessons:
- Petabyte-scale experiments require substantial time buffers — Murphy's Law hits hard at this scale.
- Standard benchmarks like YCSB need modifications to work properly at petabyte volumes.
- "Identical" hardware can behave very differently under extreme load — deeper hardware diagnostics are essential.
- Infrastructure complications (hardware failures, software bugs, configuration mismatches) dominate practical timelines far more than the actual database operations.
- Distributed PostgreSQL can absolutely handle petabyte-scale loads, but you need to be prepared for the journey.
FAQ
What is this article about in one sentence?
This article explains the core idea in practical terms and focuses on what you can apply in real work.
Who is this article for?
It is written for engineers, technical leaders, and curious readers who want a clear, implementation-focused explanation.
What should I read next?
Use the related articles below to continue with closely connected topics and concrete examples.





