How I Won the RAG Challenge: From Zero to State-of-the-Art in One Competition
A detailed technical walkthrough of the winning RAG Challenge solution, covering PDF parsing with Docling, FAISS vector indexing, LLM-based reranking, and carefully crafted prompt engineering that outperformed even larger models.
In this article, I'll share a detailed account of how I won the RAG Challenge — taking first place in all award categories and the overall state-of-the-art ranking. I'll walk through each stage of the system architecture, from document parsing to answer generation.
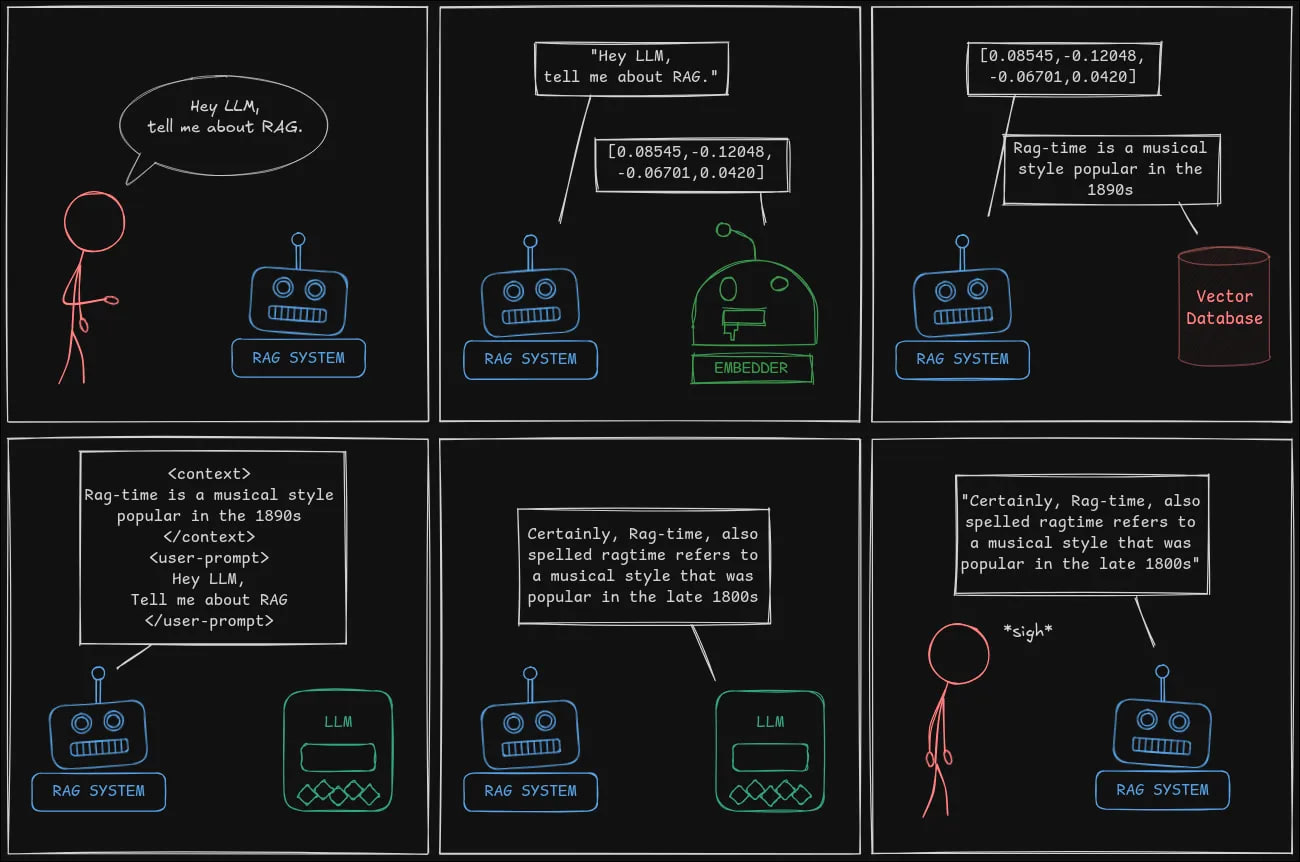
Challenge Description
Participants received 100 annual company reports as PDFs (up to 1,000 pages each) with 2.5 hours to parse them and build a knowledge base. Then the system had to answer 100 random questions with specific formats: yes/no, company names, position titles, or metrics (revenue, store count, etc.). Each answer required page references as proof. The total processing time for all 100 questions was limited to 10 minutes.
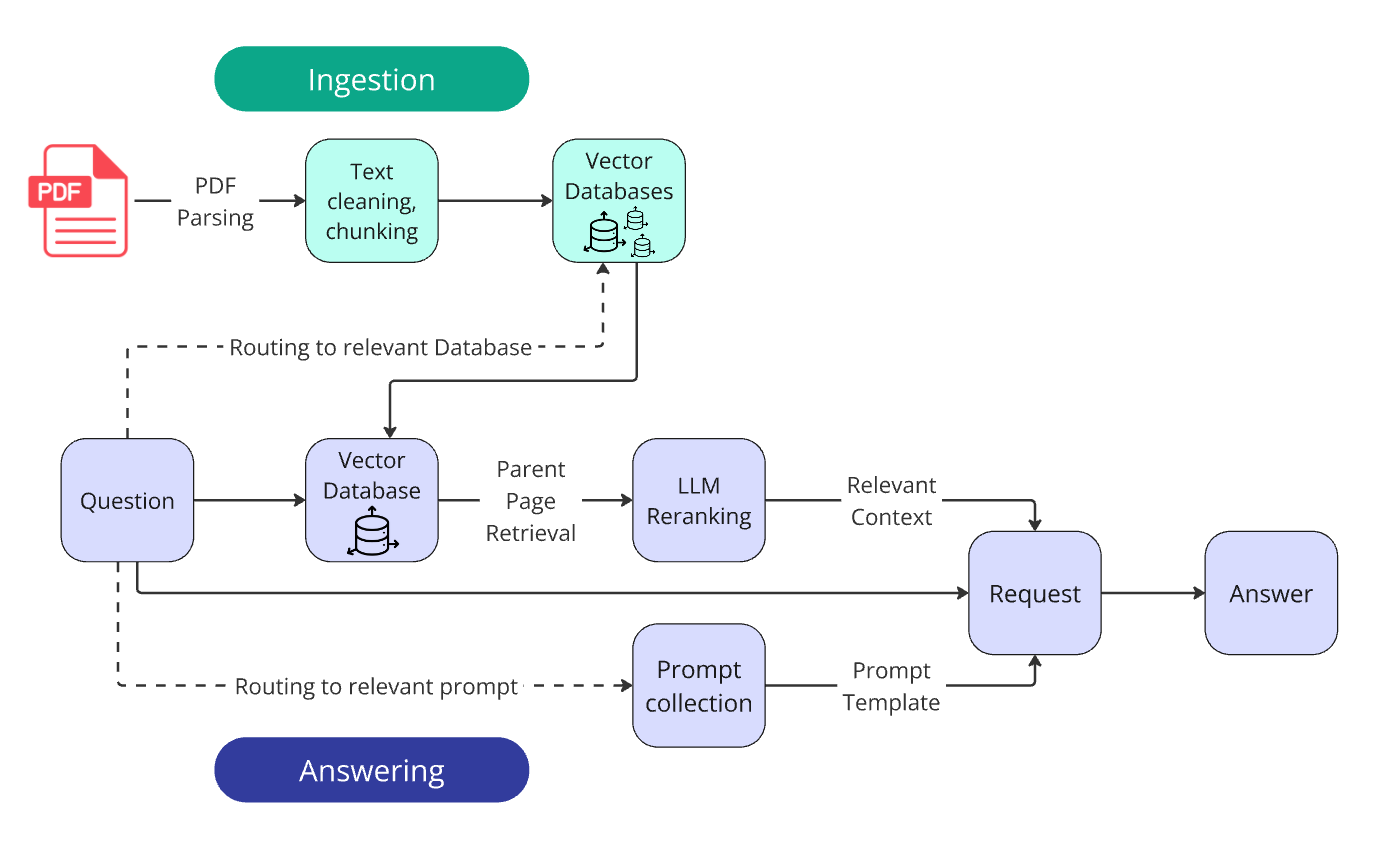
1. Parsing (PDF Extraction)
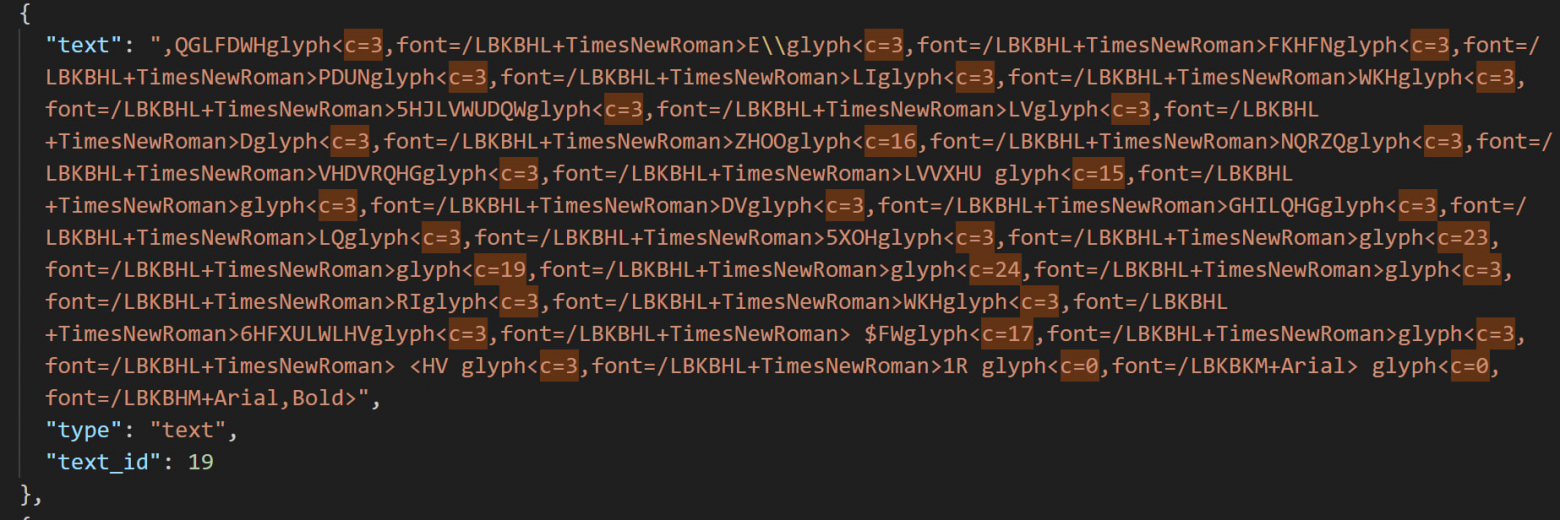
I tested dozens of PDF parsers and selected Docling as the superior choice — created by IBM, which happened to be one of the challenge organizers. The key challenges in parsing annual reports included:
- Tables rotated 90 degrees
- Mixed image-text graphics
- Caesar cipher-encoded fonts with non-uniform ASCII shifts
- Multi-column text recognition
I modified Docling's source code to output JSON with metadata, then generated both Markdown and HTML formats. Using GPU acceleration (renting an RTX 4090 at $0.70/hour), I parsed all 15,000 pages in approximately 40 minutes.
For text cleaning, I applied 20+ regex patterns to fix malformed parsing and OCR-processed problematic documents.
2. Table Serialization
Large tables presented a semantic distance problem — column headers were separated by 1,500+ irrelevant tokens from the values they described. I experimented with table serialization, converting them into sentence pairs like:
{"subject_core_entity": "Shareholders' equity",
"information_block": "Shareholders' equity for the years from 2012/3 to 2022/3 are as follows: ¥637,422 million (2012/3), ¥535,422 million (2013/3), ¥679,160 million (2014/3), ..."}However, serialization didn't improve the final winning solution because "Docling parses tables well enough, retrievers find them effectively, and LLMs understand their structure." In fact, serialization actually decreased quality in my configuration testing.
3. Ingestion
Chunking strategy: I split pages into 300-token chunks (~15 sentences) with 50-token overlaps using a recursive splitter with a custom Markdown dictionary.
Vectorization: I created 100 separate FAISS indices (one per document) rather than mixing all companies together. This used:
- IndexFlatIP format — brute-force search with Inner Product similarity
- text-embedding-3-large model for vectorization
The reasoning: keep the search domain focused. The answer is always within one document, so there's no need to search across all companies.
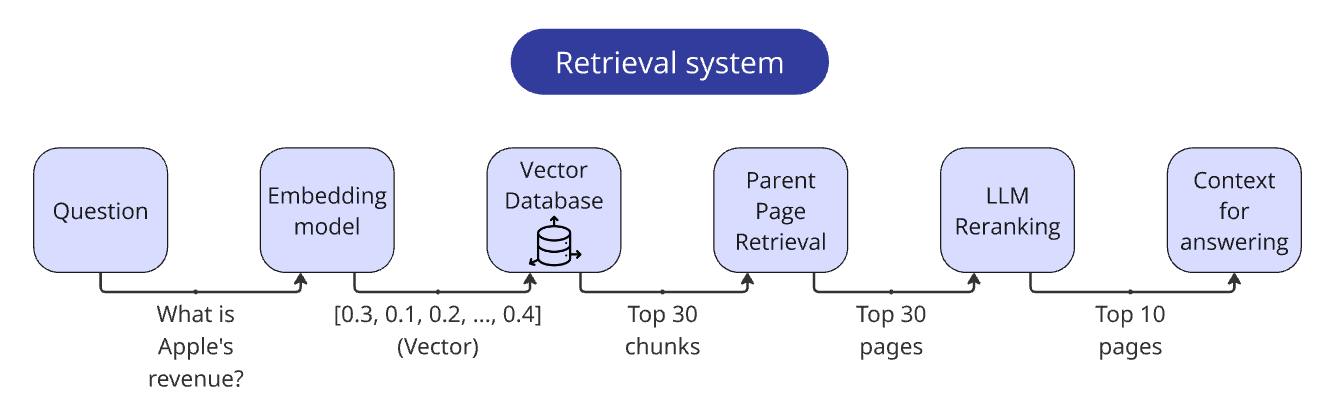
4. Retrieval Pipeline
This was the most impactful stage. The key techniques:
LLM Reranking (the single most effective method):
- Retrieved top 30 chunks via vector search
- Extracted parent pages from chunk metadata
- Sent pages to gpt-4o-mini with a detailed scoring rubric (0.0 = Completely Irrelevant through 1.0 = Perfectly Relevant)
- Used Structured Output for JSON responses
- Combined vector score (weight: 0.3) with LLM score (weight: 0.7)
- Batched 3 pages per request for efficiency (~$0.01 per question)
The Pydantic schema for LLM reranking:
class RetrievalRankingSingleBlock(BaseModel):
"""Rank retrieved text block relevance to a query."""
reasoning: str = Field(
description="Analysis of the block, identifying key information
and how it relates to the query"
)
relevance_score: float = Field(
description="Relevance score from 0 to 1, where 0 is
Completely Irrelevant and 1 is Perfectly Relevant"
)Other methods considered:
- Hybrid search (vector DB + BM25): Mostly decreased quality in my setup
- Cross-encoder reranking: Too slow for batch processing
- Parent page retrieval: Used to return full pages instead of individual chunks — this proved valuable
Final retriever workflow:
- Vectorize the question
- Find the top 30 relevant chunks
- Deduplicate and extract parent pages
- Rerank pages via LLM
- Return the top 10 ranked pages with page numbers

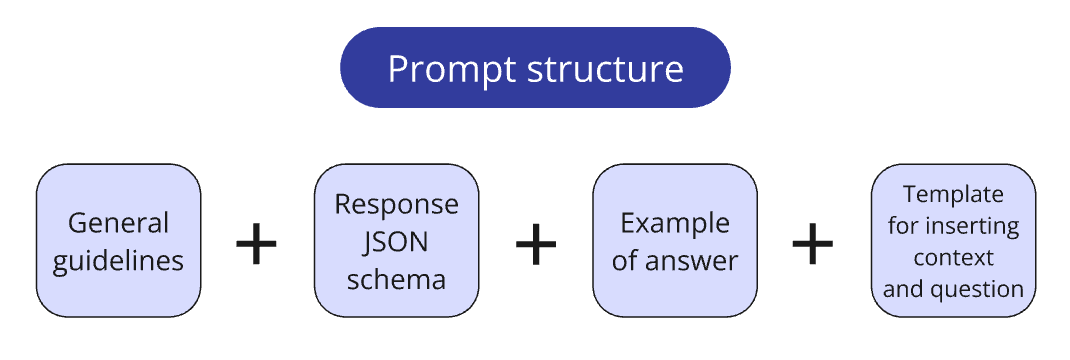
5. Generation and Prompting
Query routing:
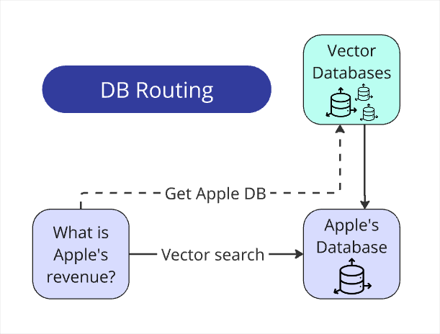
- Database routing: Extracted company names via regex matching against the provided list
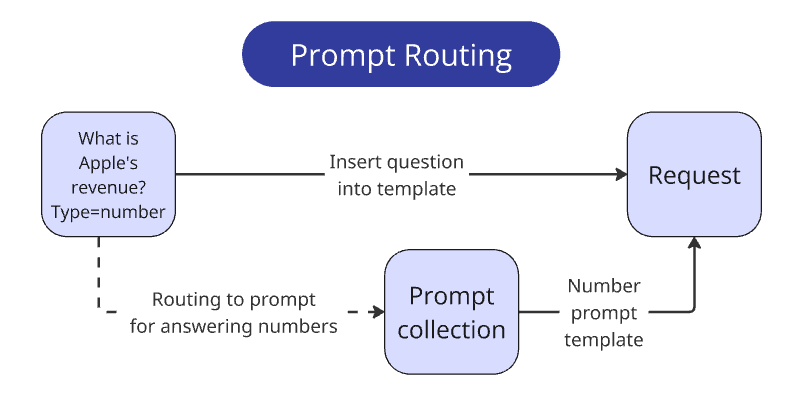
- Prompt routing: Different prompts for each answer type (number, name, boolean, comparative)
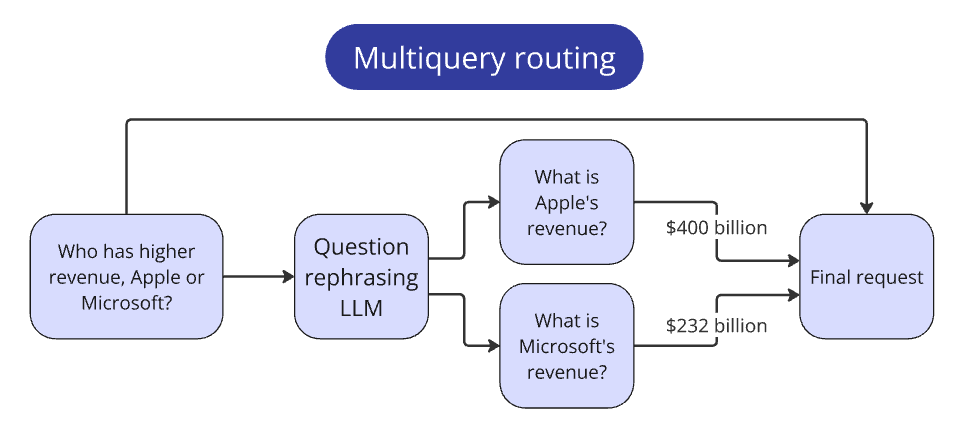
For multi-company comparisons, I decomposed the query into sequential single-company queries, then synthesized results.
Prompt engineering techniques:
Chain of Thought (CoT): Forced models to reason through steps before answering, preventing shortcuts and hallucinations. This was especially important for careful metric comparison to avoid "gravity" toward incorrect adjacent values in tables.
Structured Outputs: Defined Pydantic schemas with four fields:
step_by_step_analysis— reasoning processreasoning_summary— condensed logicrelevant_pages— page referencesfinal_answer— single response in required format
One-shot examples: Included meticulously crafted example Q&A pairs demonstrating ideal reasoning patterns and JSON structure.
SO Reparser: A fallback method validating LLM responses against the schema; if invalid, returned the answer to the LLM for correction — achieved 100% compliance.
Instruction refinement: I manually reviewed dozens of answer examples and iteratively corrected prompt directives, addressing tasks like:
- Currency normalization (different units: thousands vs. millions)
- Role name interpretation (CEO vs. Managing Director across regions)
- Negative value detection (parentheses indicating negative numbers)
6. System Performance and Configuration
Speed: Processed all 100 questions in 2 minutes (well under the 10-minute requirement) using parallel processing at OpenAI's Token Per Minute limits.
I created a flexible configuration system to test whether each technique actually improved results:
class RunConfig:
use_serialized_tables: bool = False
parent_document_retrieval: bool = False
use_vector_dbs: bool = True
use_bm25_db: bool = False
llm_reranking: bool = False
llm_reranking_sample_size: int = 30
top_n_retrieval: int = 10
api_provider: str = "openai"
answering_model: str = "gpt-4o-mini-2024-07-18"Key finding: serialization actually decreased quality.
Model performance comparison:
- gpt-4o-mini: Best efficiency/cost ratio
- o3-mini: Slight improvements over gpt-4o-mini
- Llama 3.3 70B: Only 2-3 points behind OpenAI models
- Llama 8B: Outperformed 80% of competitors with proper prompting
Critical Insights
"Junk in — Junk out": Retrieval quality is paramount. Poor context makes LLM answers irrelevant regardless of other optimizations.
"Threshold of interpretation freedom": Questions have inherent ambiguities (What counts as "CEO"?) requiring explicit calibration rather than hoping LLMs infer intent.
"Semantic chunking": While small chunks improve vector search relevance, parent page retrieval recovers the secondary context needed for accurate answers.
Prompt structure matters more than model size: Even small models following detailed instructions outperformed generic approaches with larger models.
Key Statistics
- 100 documents totaling ~15,000 pages
- 100 validation questions for testing
- 2.5-hour parsing window
- Vector search: top 30 → LLM rerank → top 10
- LLM reranking cost: less than $0.01 per question
- Total processing time for 100 questions: 2 minutes

The complete codebase is available on GitHub. The main takeaway: RAG magic is hidden in the details — systematic optimization across all pipeline stages, not any individual technique, drove the success.



