How ChatGPT Works: The Evolution of Language Models from T9 to a Miracle
A comprehensive accessible explanation of how ChatGPT works, tracing the evolution from T9 predictive text through neural networks, Transformers, GPT-1/2/3, RLHF, and finally ChatGPT — with analogies and minimal math.
ChatGPT is T9 from your phone, but on steroids. Both technologies do the same thing — predict the most likely next word based on the preceding text. The only difference is scale. Let's trace how we got from the primitive word-prediction of 2000s phones to a system that writes poetry, code, and passes professional exams.
Part 1: Predicting the Next Word
T9 and the Art of Prediction
Remember T9 on old phones? You press a few keys and the phone guesses which word you want. It works by analyzing letter frequency statistics: after the combination "th", the letter "e" is more likely than "z". Simple probability.
Now imagine a T9 that has read the entire internet. That's essentially what a language model is — a system that predicts the next word based on everything that came before it. The better the system understands the context, the more sensible its predictions.

From Statistics to Neural Networks
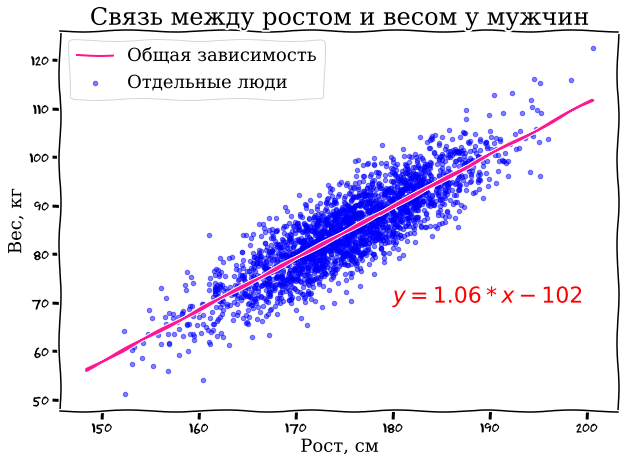
Let's start with a simple analogy. Imagine you have data about people: their height and weight. You want to predict weight from height. You draw a graph, scatter the data points, and draw a straight line through them — this is linear regression, the simplest mathematical model.
The equation of this line has two parameters: slope and intercept. By adjusting these two numbers, you can fit the line to the data. A neural network does exactly the same thing, but instead of two parameters, it has millions or billions of them, and instead of a straight line, it fits incredibly complex curves through incredibly complex data.

Why Probabilities and Not Exact Answers?
A key concept: language models work with probabilities. If you start a sentence with "Barack", the model might assign 90% probability to the next word being "Obama", 5% to "Hussein", and distribute the remaining 5% across other words. This probabilistic approach is actually what gives the model its "creativity" — by sometimes choosing less probable words, the model generates diverse and interesting text rather than repeating the same phrases.
Part 2: The Rise of Transformers
GPT-1 and the Transformer Architecture (2018)
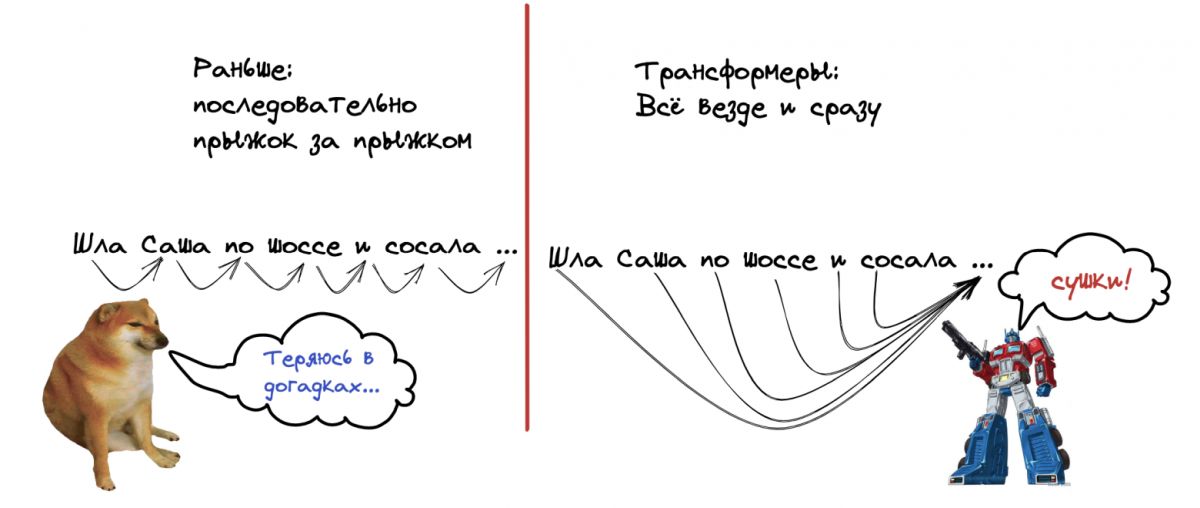
Before Transformers, language models processed text sequentially — word by word, left to right. This was slow and meant the model quickly "forgot" the beginning of a long sentence by the time it reached the end.
The Transformer architecture, invented by Google researchers in 2017, changed everything. The key innovation was the attention mechanism — the ability to look at all words in the input simultaneously and determine which ones are most relevant to each other. Instead of reading a sentence from left to right, the Transformer looks at everything at once, like a human scanning a page.
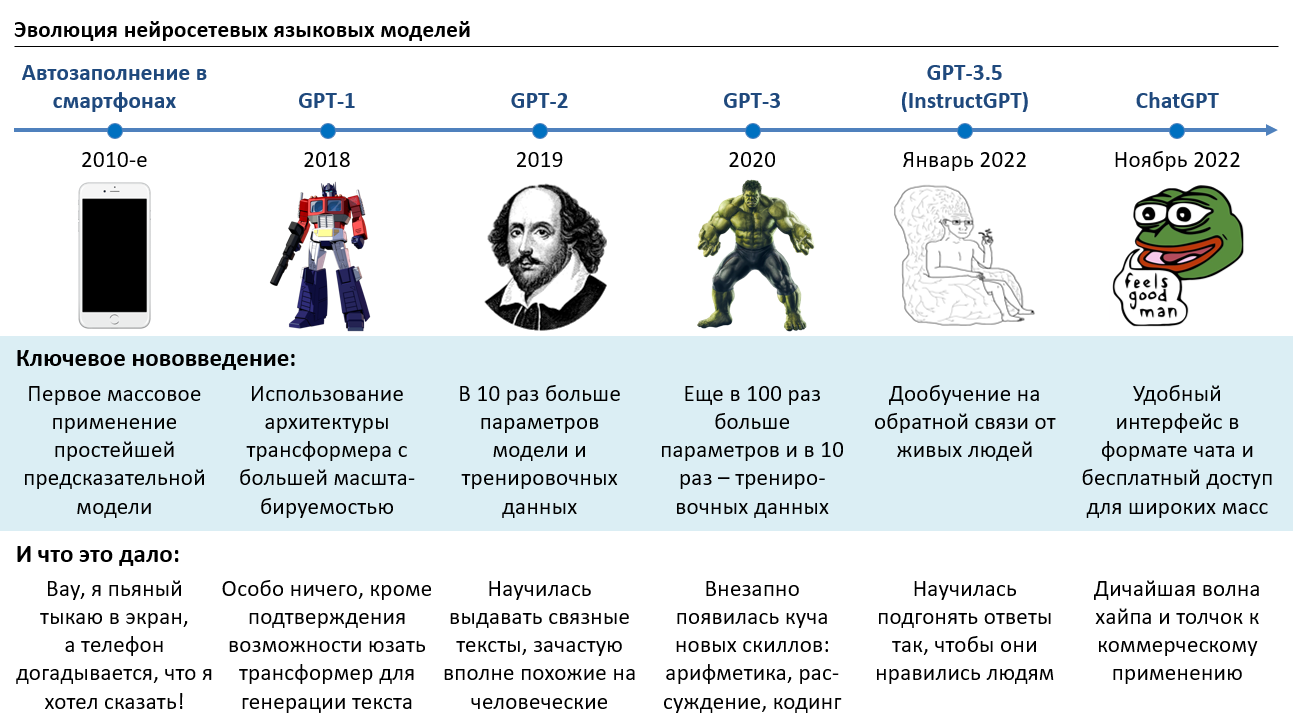
GPT-1 (Generative Pre-trained Transformer) was the first model to combine this architecture with pre-training on large amounts of text. It had 117 million parameters — a lot by 2018 standards, but tiny by today's.
GPT-2 (2019): When Quantity Becomes Quality
GPT-2 was a radical scaling experiment. The training data grew from a few gigabytes to 40 GB of text scraped from Reddit links — roughly equivalent to seven thousand copies of Shakespeare's complete works. The model size jumped to 1.5 billion parameters.
And then something unexpected happened. The model could suddenly do things nobody had explicitly taught it: write coherent essays, complete stories in a given style, translate between languages (poorly, but still), and even do basic arithmetic. None of these abilities were programmed — they emerged from the sheer scale of data and parameters.
OpenAI was so concerned about misuse that they initially refused to release the full model, publishing only a smaller version. This decision was controversial but generated enormous publicity.
GPT-3 (2020): The Emergence of Reasoning
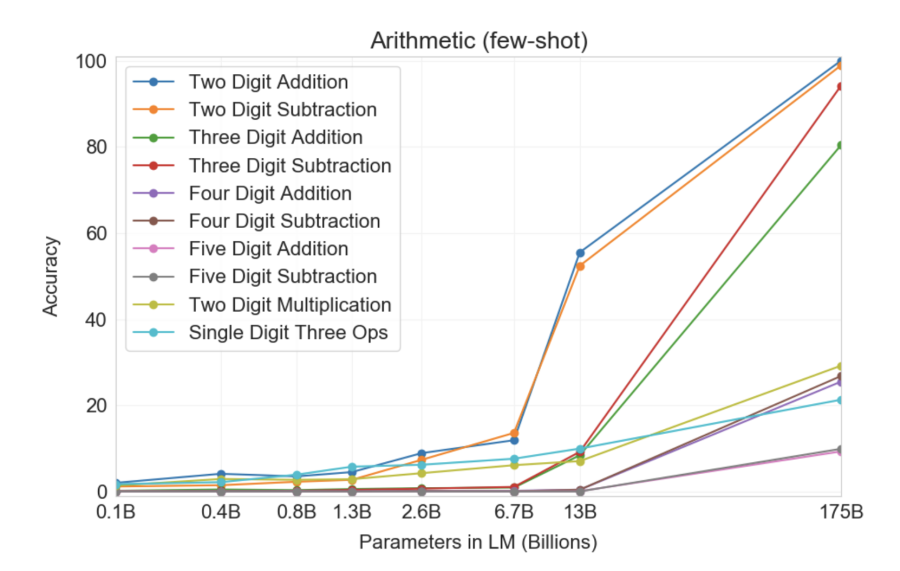
GPT-3 made another enormous leap: 175 billion parameters trained on 420 GB of text. At this scale, truly astonishing capabilities emerged:
- Arithmetic: The model could add and multiply numbers, despite never being explicitly trained on math.
- Translation: High-quality translation between dozens of language pairs.
- Reasoning: Given the right prompts, the model could solve logic problems step by step.
- Code generation: It could write working programs from natural language descriptions.
Scaling Laws and Emergent Abilities
One of the most fascinating discoveries was that these abilities don't emerge gradually. You don't see a model slowly getting better at arithmetic as you add parameters. Instead, performance is essentially zero — and then at some critical threshold, it suddenly jumps to near-perfect. This is called an emergent ability, and it's what makes predicting the capabilities of future, larger models so difficult.

Part 3: Prompting — The Art of Asking
Few-Shot Learning
One of GPT-3's surprises was that its performance depended heavily on how you asked the question. Give the model a bare math problem and it might get it wrong. But show it a few examples first ("few-shot learning"), and accuracy skyrockets.
Even more remarkably, simply adding the phrase "Let's think step by step" before a math problem dramatically improved accuracy. This technique, called chain-of-thought prompting, essentially asks the model to show its work, and in doing so, the intermediate reasoning steps help it arrive at the correct answer.

Part 4: Teaching the Model Manners
InstructGPT / GPT-3.5 (January 2022)
Raw GPT-3 was powerful but also uncontrollable. Ask it a question and it might continue the text as if it were a random internet forum post rather than actually answering you. It could produce toxic, biased, or simply unhelpful content because that's what a lot of the internet looks like.
The solution was Reinforcement Learning from Human Feedback (RLHF). The process worked in three stages:
- Supervised fine-tuning: Human trainers wrote example responses to prompts, showing the model what a good answer looks like.
- Reward model training: Humans ranked multiple model outputs from best to worst. A separate model was trained to predict these human preferences.
- Reinforcement learning: The language model was optimized to maximize the reward model's scores — essentially learning to produce responses that humans would rate highly.
The result was InstructGPT — a model that actually tries to help you, follows instructions, admits when it doesn't know something, and avoids harmful content. Technically, it was a relatively small change. In terms of user experience, it was transformative.

ChatGPT (November 2022): The Interface Revolution
Here's the surprising part: ChatGPT introduced almost no new technical innovations. It was essentially InstructGPT with some additional fine-tuning for dialogue. The model architecture was the same, the training approach was largely the same.
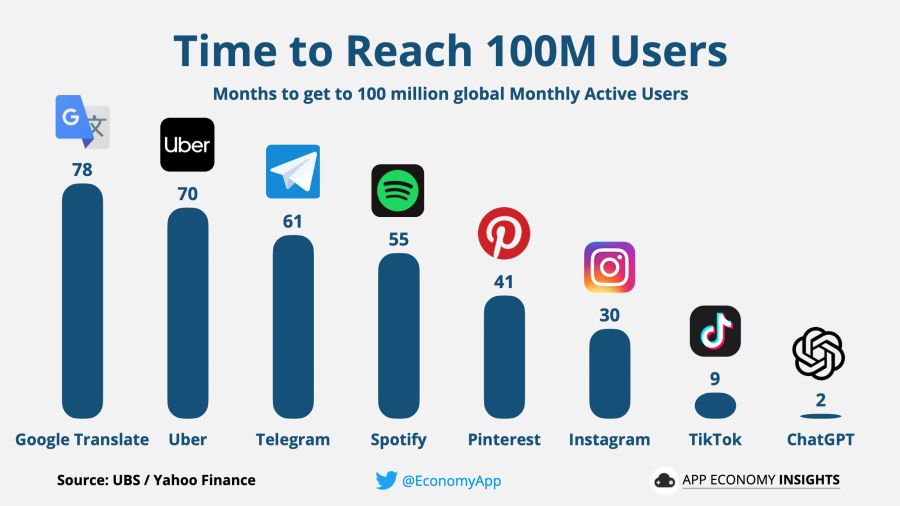
The real breakthrough was the interface. By wrapping the model in a simple chat interface and making it freely available, OpenAI turned an obscure research project into a global phenomenon. Within five days, ChatGPT had a million users. Within two months — over 100 million.
The main secret of ChatGPT's success was simply a convenient interface. That's it. The technology was ready months before — it just needed someone to put it in a chat window and let people play with it.
Part 5: What's Under the Hood?
Tokens, Not Words
Language models don't actually work with words — they work with tokens, which are fragments of words. The word "unbelievable" might be split into "un", "believ", "able". This allows the model to handle any word, even ones it has never seen before, by assembling it from familiar pieces. GPT-3 uses a vocabulary of about 50,000 tokens.
Context Window
Every language model has a limited context window — the maximum number of tokens it can process at once. For GPT-3, this was 4,096 tokens (roughly 3,000 words). Everything outside this window is effectively invisible to the model. This is why ChatGPT can "forget" the beginning of a long conversation — it literally cannot see it anymore.
Temperature and Creativity
Remember how the model assigns probabilities to possible next words? The temperature parameter controls how these probabilities are used. At temperature 0, the model always picks the most probable word — producing deterministic, repetitive text. At higher temperatures, lower-probability words get a bigger chance of being selected, making the output more creative but also more unpredictable. ChatGPT uses a moderate temperature to balance coherence and variety.

Conclusion
The path from T9 to ChatGPT is, fundamentally, a path of scaling. The basic idea — predict the next word — hasn't changed. What changed is the amount of data, the number of parameters, the architecture that processes them, and the human feedback that shapes behavior.
We deliberately simplified much of the technical detail in this article. We didn't dive into the mathematics of attention mechanisms, positional encodings, or the details of the optimization process. Our goal was conceptual understanding: what these systems do, how they evolved, and why ChatGPT specifically became a phenomenon.
In future articles, we plan to address the harder questions: Is the model actually "thinking"? What are the risks of these systems? How do corporate incentives shape AI development? Stay tuned.