Deep Kubernetes health checks
Distributed systems are often characterized as a double-edged sword. There is a lot of great material on the Internet about both their ugly and great sides. But this post is of a slightly different nature. In general, I am usually in favor of distributed systems in cases where th
Editor's Context
This article is an English adaptation with additional editorial framing for an international audience.
- Terminology and structure were localized for clarity.
- Examples were rewritten for practical readability.
- Technical claims were preserved with source attribution.
Source: original publication
Distributed systems are often characterized as a double-edged sword. There is a lot of great material on the Internet about both their ugly and great sides. But this post is of a slightly different nature. In general, I am usually in favor of distributed systems in cases where they are really needed, but in this post I will tell you how one of my mistakes when working with a distributed system led to far-reaching consequences.
The mistake I made now happens in many companies and can lead to an avalanche of failures. Let's call her deep health checking in Kubernetes.
Kubernetes is a container orchestration platform. It is no coincidence that Kubernetes is popular among specialists building distributed systems, as it allows you to formalize the infrastructure in the form of a reasonable native cloud abstraction. With this abstraction, developers can configure and run applications without having to be networking experts.
Kubernetes allows and recommends configuring several types of probes: liveness, readiness, and startup. These probes are conceptually simple and can be described as follows:
With the help viability samples we tell Kubernetes whether the container needs to be restarted. If the viability test is negative, the application will restart. This method can catch certain problems - such as deadlocks - and allow access to the application again. For example, colleagues from Cloudflare described Here, how to restart stuck Kafka consumers in this way.
Readiness tests are used only with http-based applications, and such probes allow you to signal that the container is ready to receive traffic. A pod is considered ready to receive traffic when all its containers are ready. If any container in a pod fails the readiness test, it is removed from the service load balancer and will not receive any HTTP requests. But, if the readiness test fails, then the device does not restart, but if the viability test fails, then it restarts.
Launch trials Typically recommended for use with legacy applications that take a significant amount of time to launch. Once an application passes the run tests, subsequent liveness and readiness tests are not taken into account.
In the remainder of this post, we'll focus on readiness probes as they apply to HTTP-based applications.
❯ When will my application be ready?
At first glance, a very simple question, right? “The application is ready to go as soon as it can respond to user requests,” you might say. Consider a payment company app where you can check your balance. When a user opens a mobile app, it sends a request to one of the many backend services you have. The service receiving the request must then:
Validate the user token by contacting the authentication service.
Call the service where the balance is maintained.
Send an event to Kafka
balance_viewed.(Via another endpoint) allow the user to close their account, causing a row to be updated in that service's own database.
Therefore, it can be argued that the successful operation of an application serving users depends on:
Authentication service availability
Availability of service for checking balance
Kafka Availability
Availability of our database
The graph of these dependencies will look something like this:
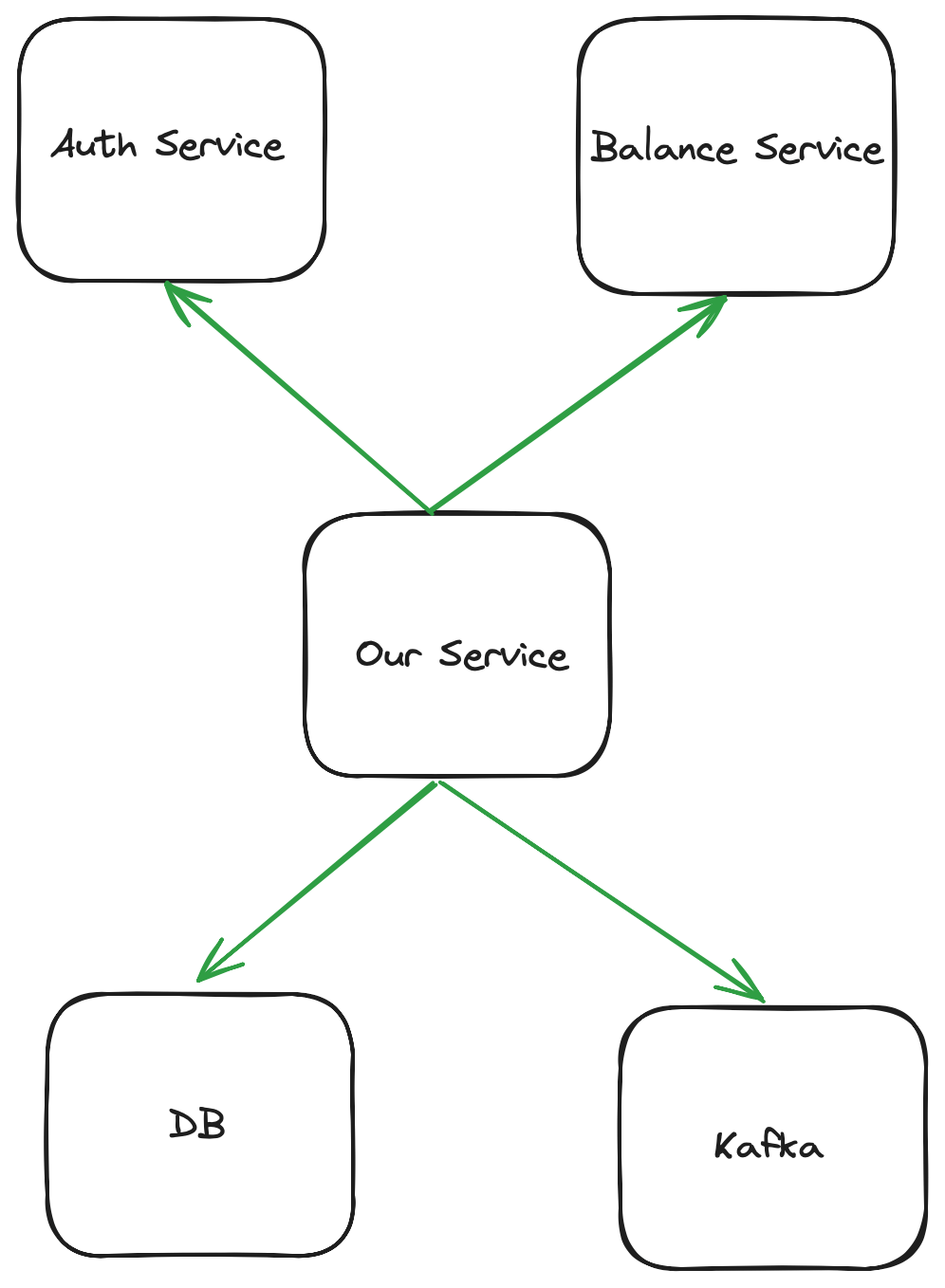
Therefore, it is possible to write a readiness endpoint that returns JSON and code 200 if all of the above is available:
{ "available":{ "auth":true, "balance":true, "kafka":true, "database":true } }
In this case, “availability” may be understood slightly differently for different elements:
When working with authentication and balance services, we need to make sure that we receive the code
200from their ready endpoints.Working with Kafka, we make sure that we can issue an event to a topic called healthcheck.
Working with the database, we perform
SELECT 1;
If any of these operations are unsuccessful, we will return false for JSON key and also HTTP error 500. This situation is considered a failure of the readiness probe, and as a result, Kubernetes will remove this pod from the service load balancer. At first glance, this may seem reasonable, but in fact, this practice sometimes leads to an avalanche of failures. Thus, we, perhaps, nullify one of the most significant advantages of microservices (failure isolation).
Imagine the following scenario: the authentication service has failed, and all other services used in our company rely on it for deep readiness checking:
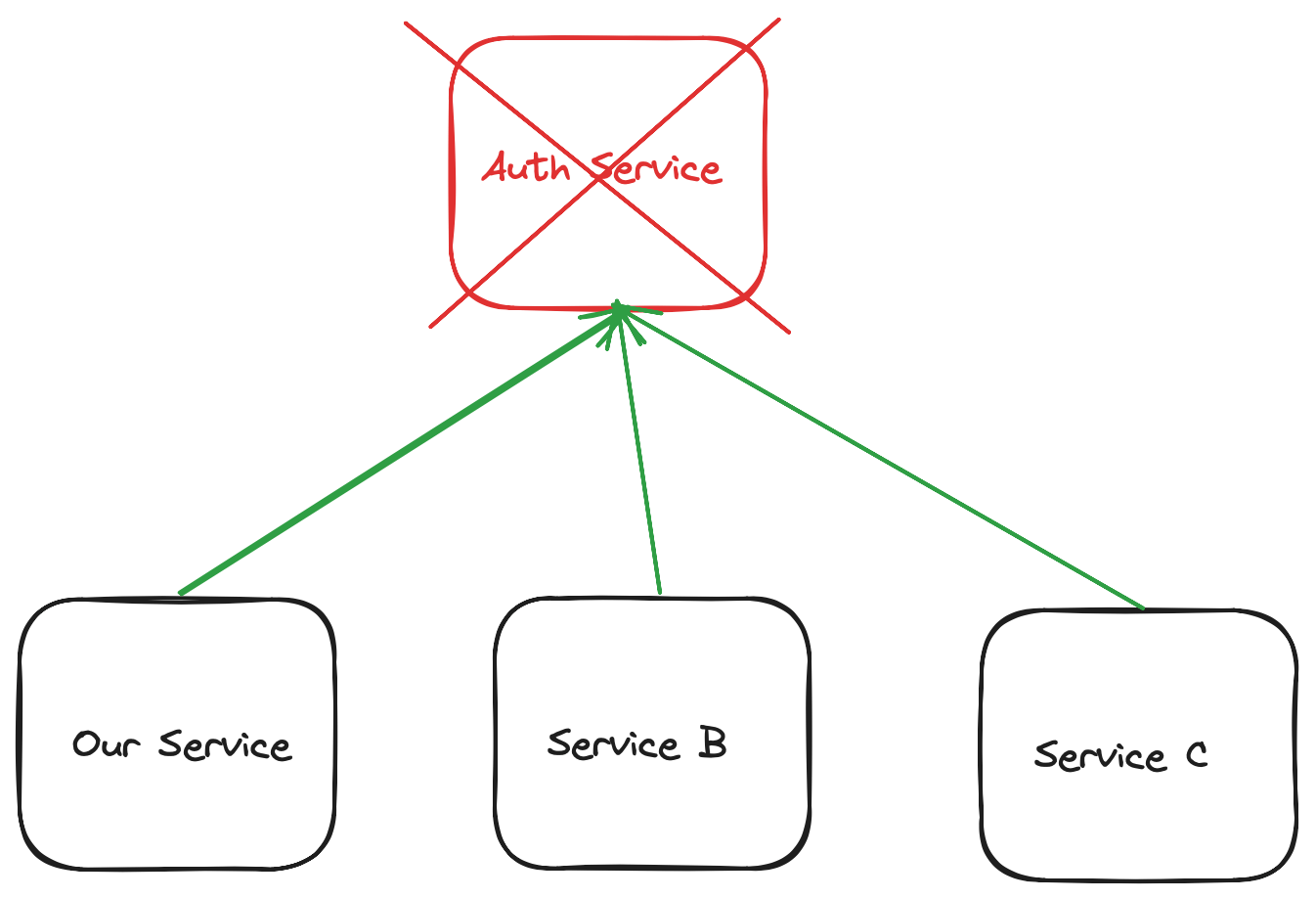
In this case, due to the failure of the authentication service, all our pods will be removed from the load balancing service. The refusal will become global:
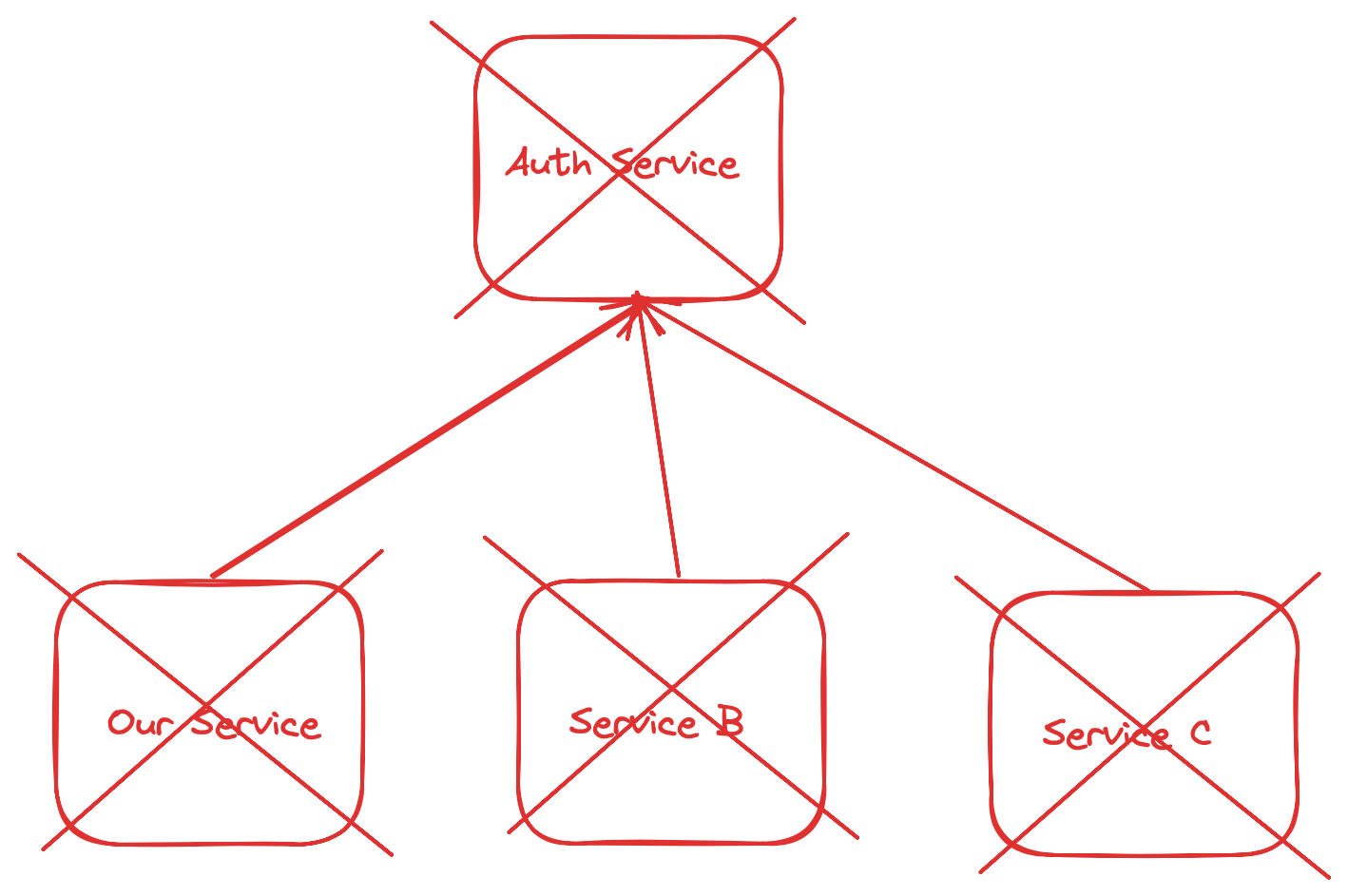
Worse, we will have almost no metrics by which to determine the cause of this failure. Since requests don't reach our pods, we don't know how much to increase all those Prometheus metrics that we've carefully placed in our code. Instead, we will have to carefully consider all those pods that are marked as unready in our cluster.
After this, we will have to reach the end point responsible for their readiness in order to identify which dependency caused the failure and then trace the entire tree. The authentication service could be down because one of its own dependencies failed.
Something like this:
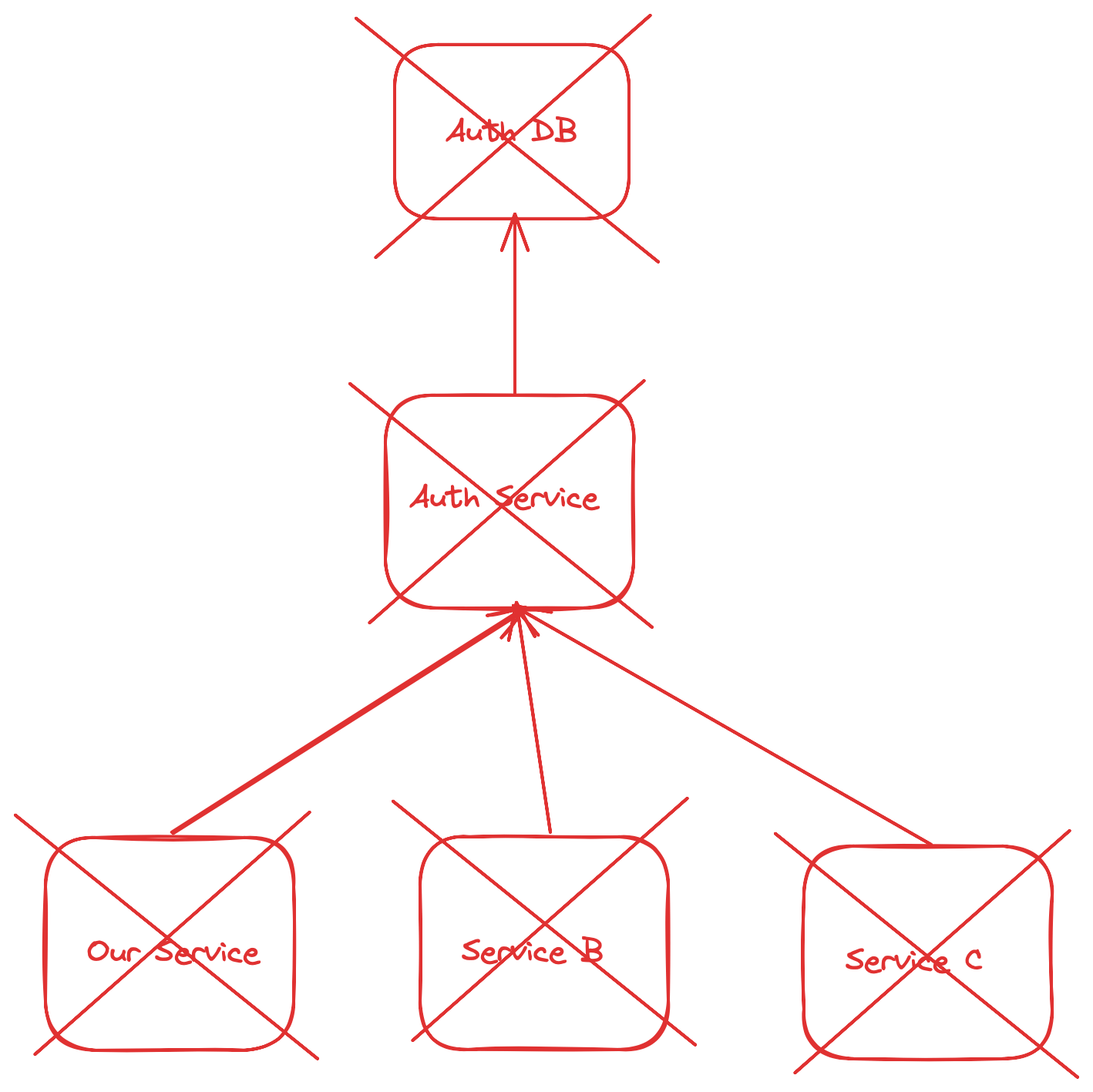
In the meantime, our users see the following:
upstream connect error or disconnect/reset before headers. reset reason: connection failure
Not the best quality error message, right? We can and will do much better.
❯ So how do you judge the readiness of an application?
The application is ready if it can produce a response. This could be a failure response, but in that case it still executes some of the business logic. For example, if the authentication service fails, then we can (and should) first try again, programming an exponential delay, meanwhile increasing the value of the failure counter. If any of these counters reach a threshold that you deem unacceptable (according to the SLOs defined in your organization), then you can declare an incident with a clearly defined impact zone.
It is hoped that during this time, individual segments of your business system will be able to continue operating, since not the entire system was dependent on this failed service.
Once the incident is fixed, you should consider whether the service needs this dependency and what can be done to get rid of it. For example, is it possible to move to an authentication model that is less stateful? Can I use the cache? Is it possible to automatically interrupt certain sequences of user actions? Should some of the worker threads that don't require as many dependencies be moved to another service to better isolate failures in the future?
Based on conversations with colleagues, I can assume that this post will turn out to be quite holivar. Some might think I'm an idiot just because I implement deep sanity checks at all, since naturally they can lead to avalanche-like failures. Others will share this post on their feeds and ask, “Are we testing doneness incorrectly?” - and here the lord will intervene in the discussion and begin to prove that their case is special, therefore such checks are advisable for them. Maybe so, in which case I would like to read more about your situation.
By creating a distributed system, we further complicate it. When working with distributed systems, you should always show healthy pessimism and immediately think about possible failures. I mean, don't expect rejection all the time, but just be prepared for it. We need to understand the interconnected nature of our systems and know that from a single point of failure, problems spread out like ripples on water.
The main takeaway from my Kubernetes story is not to abandon deep health checks entirely, but to use them carefully. There is a very important balance here: weighing the merits of detailed performance checks against the likelihood of widespread system failure. We improve as developers when we learn from our mistakes and help others do the same. This is how we manage to remain resilient while working with increasingly complex systems.
— Matt
News, product reviews and competitions from the Timeweb.Cloud team — in our Telegram channel ↩

📚 Read also:
➤ Requests and limits in Kubernetes: understanding the details;
➤ Large-scale video streaming using Kubernetes and RabbitMQ;
➤ Experience scaling Kubernetes to 2k nodes and 400k pods;
➤ A Guide to Kubernetes for Kubernetes Haters;
➤ Ephemeral containers in Kubernetes.
Why This Matters In Practice
Beyond the original publication, Deep Kubernetes health checks matters because teams need reusable decision patterns, not one-off anecdotes. Distributed systems are often characterized as a double-edged sword. There is a lot of great material on the Internet about both their ugly...
Operational Takeaways
- Separate core principles from context-specific details before implementation.
- Define measurable success criteria before adopting the approach.
- Validate assumptions on a small scope, then scale based on evidence.
Quick Applicability Checklist
- Can this be reproduced with your current team and constraints?
- Do you have observable signals to confirm improvement?
- What trade-off (speed, cost, complexity, risk) are you accepting?
FAQ
What is this article about in one sentence?
This article explains the core idea in practical terms and focuses on what you can apply in real work.
Who is this article for?
It is written for engineers, technical leaders, and curious readers who want a clear, implementation-focused explanation.
What should I read next?
Use the related articles below to continue with closely connected topics and concrete examples.





