As we wrote at VK Cloud SDN
With the advent of broadband access and high speeds of mobile Internet, network load has become one of the key bottlenecks for system performance. Network providers are faced with the need to continually increase and optimize network throughput and capacity while maintaining prof
Editor's Context
This article is an English adaptation with additional editorial framing for an international audience.
- Terminology and structure were localized for clarity.
- Examples were rewritten for practical readability.
- Technical claims were preserved with source attribution.
Source: original publication

With the advent of broadband access and high speeds of mobile Internet, network load has become one of the key bottlenecks for system performance. Network providers are faced with the need to continually increase and optimize network throughput and capacity while maintaining profits. An attempt to solve this problem was the Software Defined Network - the concept of moving network functions from specialized hardware to the software level and further dividing responsibilities into different layers.
Since the existence of SDN, many reasons have emerged to use this approach:
- cost reduction at all levels - it is easier to manage the network state and infrastructure, clearer scaling and fault tolerance, clear architecture with a central controller;
- the ability to automatically configure and adjust the network;
- availability of conditionally infinite flexibility in setting up traffic processing logic;
- simplifying the inventory of network elements - for example, automating the removal of objects upon failure or disposal and rebalancing the network state;
- moving towards vendor-neutral solutions (which is especially important).
Although the latest developments and attention are relatively recent, the principles and foundation for the Software Defined Network have been laid over the past decades. We are in VK Cloud We are also making our own SDN called Sprut. Several years ago, developers began migrating to it from the previous one, Neutron. We asked them what's going on with the development of the new SDN.
Below the cut is the history of SDN for those who are not immersed in the context. And if you already know, then skip and read on.
History of SDN
Long time ago…
Computer networks are not easy to administer. Lots of equipment: routers, switches. A lot of software: firewalls, NAT, balancers, security. On routers and switches, the control software is usually complex, closed and proprietary; it implements protocols and functionality. All this together is constantly rethought, standardized and tested in work with other technologies. The wealth of technology and the love of developing everything on your own slowed down innovation quite a lot, increasing complexity and all types of costs.
The first “approaches to the projectile” were taken back in the mid-1990s, when Active Networking technology embodied programmable functions at the network level. During this period, the Internet acquired new scenarios, and it became clear that it was not enough to make do with current approaches to the development and support of networks. Load modeling and communication with the IETF began to standardize new approaches.
If you are interested in reading more about these initiatives, you can study GENI (Global Environment for Network Innovations), NSF FIND (Future Internet Design), EU FIRE (Future Internet Research and Experimentation Initiative).
Key interesting trends during this period include:
- programmable functions to reduce the barrier to innovation. Lack of flexibility was one of the key reasons for the development of SDN. At this stage, much attention was paid to programming the data layer. Over time, there has been more investment in SDN protocols such as OpenFlow, FlowVisor, etc.;
- virtualization and demultiplexing,rules based on packet headers.
Research was carried out on all fronts - from architecture, hardware and performance to security issues. There were studies about whether it was safe to make the network more active if malicious applications could pass through it; at that time, Java was most mentioned.
Active Networking was a radical change. Previously, it was impossible to program networks, but now it has become possible to extend the API to the resources of network nodes (processing, queues) and packet processing. At that time, not everyone supported this idea; there were supporters of the approach “the simpler the better, but programming networks is already difficult and simply ideologically wrong.” The problem with Active Networking was the lack of market support for the comprehensive solutions it offered. An additional problem was related to geography: different regions of the planet have different standards, and proprietary designs sometimes did not take this into account, complicating network processes. The attempt to change the situation at that time failed.
Later, from about 2000 to 2007, research continued on narrower and more understandable tasks: routing, configuration management, and separation of responsibilities. During this period, implementations of the main characteristic of SDN began to crystallize: a clear separation of functionality in the Control and Data layer. The Control layer manages traffic, the Data layer is responsible for developing control layer solutions. The Control layer was more open to innovation than the Data layer, so the focus was on it.
The research was greatly helped by the reduction in the cost of computing resources: it turned out that the servers had much more resources than were allocated in the routers to the control layer.
At this stage, two directions emerged:
Open interface between layers, which needed to be standardized in the IETF, and interfaces for working with packages at the Linux kernel level. The ForCES working group put forward proposals for the interface, an important part of which was the proposal to use an API to set rules for traffic in the data layer. By this logic, it would be possible to completely remove the control layer from the router. It didn't work out. Continued to use BGP, a standard control layer protocol, to set rules on legacy routers.
Platform architecture and state management. Centralization of controllers did not help solve the problem of distributed state management, replication and failover. And if there might not have been any special problems with replicas that would justify special measures (replicas would eventually process the same routes), then scaling was a little more difficult, especially in the case of SDN controllers.
The reduction in cost of computing resources meant that one simple server could store and execute all the routing logic necessary for a large network. Additional advantages immediately emerged: making backups became much easier.
At this stage, there was still a lot of resistance to new ideas, especially at the level of architecture (how a distributed system will behave even within the same perimeter) and regulations (what to do if something breaks). There was also concern that the industry was moving away from the nice model of distributed consensus, where everyone eventually synchronizes their state. In fact, even then the nice model and implementation had flaws: for example, distributed routing protocols used routing techniques such as OSPF Area / BGP Route Reflector.
It was also logical that there would be some resistance from key players. The adoption of standards, especially open ones, meant (and continues to mean today) that new players could enter the market.
The bottom line: this period was not marked by any serious industrial shifts, but it shaped the SDN architecture as it later became. Including due to the emergence of the 4D project, which postulated SDN, consisting of four layers: Data plane (rules-based packet processing), Discovery plane (topology collection and measurement), Dissemination plane (placement of rules for packet processing), Decision plane (logical combination of controllers that implement packet processing). Defining projects appeared: Ethane, SANE. Ethane became the forerunner of OpenFlow - the system design became the first version of the OpenFlow API.
OpenFlow is a network communication protocol used for communication between controllers and switches in SDN architecture. It has traffic control tables, each rule in which indicates a part of the traffic and an action: drop, forward, flood. Packets are tracked separately, and priority is layered on top to separate rules with overlapping logic.
OpenFlow was able to find a balance in answering the logical question from critics about why make fully programmable networks without fully understanding the problems they will solve. OpenFlow expanded the functionality of early hardware without breaking the backward compatibility of what was already there. This limited the flexibility of the project itself, but OpenFlow could be deployed quickly (essentially with a firmware upgrade), which paved the way for SDN. The equipment already supported technologies that were standardized in the OpenFlow protocol, such as flexible access control and flow monitoring.
The first research and real implementations of OpenFlow began on university campuses, but the wave quickly spread to data centers, for which the model in which they could hire developers to write controllers for a large number of the same type of equipment became more profitable than buying and supporting proprietary, closed and difficult to update equipment.
Since SDN began to gain popularity, a number of working groups and consortia such as the Open Networking Foundation and the Open Daylight Initiative have formed.
OpenFlow, in fact, has become a motivator and a real case for research in the field of a network operating system that breaks network functionality into three layers: a Data plane with an open interface, a State management layer to support a consistent understanding of the state of the network, and a Control layer.
It is interesting that at this time two approaches to traffic analysis emerged. Old, classic (Ethane) - the first packet of each flow must pass through the controller. The approach of OpenFlow and other SDNs in general has been to respond only to topology changes and updates in response to transmission errors or a clogged network.
There were many protocols that extended SDN after OpenFlow. Among the interesting ones we can mention:
- NETCONF (XML over SSH) - 2006;
- RESTCONF (XML/JSON over HTTP) - 2017;
- gMNI (gRPC over HTTP2) - 2019.
Each of the protocols brought some aspect of convenience for engineers. NETCONF added RPC for working with the configuration of network elements, architectural parts for storing state and data, and the YANG language for data modeling. RESTCONF added HTTP CRUD to the equation, working with configuration. gRPC allowed us to look at working with a large amount of transferred data from a new perspective, plus HTTP2.
The active implementation of protocols and standards has made it possible to gradually move towards vendor-neutral solutions, towards the Open-Source model, where many SDN are now located. The open-source model opened up many opportunities for refinement, feedback, and integration of ecosystem components.
Today, we can say that the surge in attention to SDN happened around 2016, when Open Virtual Network (OVN) was added to OpenStack. Since then, the Linux Foundation and Open Networking Foundation have been working to standardize approaches and help projects (OpenDaylight, vSwitch, etc.) find their niche.
SDN in the cloud
SDN has become a foundational service for cloud platforms. One of the main characteristics of the cloud is elasticity. This, as well as the speed and other characteristics of deployments, imply that underlying services should be as automated as possible, tracking the life cycle of the objects on which the deployed service operates. For example, for virtual machines this could be storage and network settings. When you set up a virtual machine in any cloud and go to the networks tab to configure which subnet the virtual machine will be on, you are involved in generating a request for SDN.
SDN is an important part of network setup automation. Therefore, SDN is an integral part of any cloud product.
History of SDN development in VK Cloud
VK Cloud started with OpenStack. SDN was taken from the very beginning as part of OpenStack - Neutron. The main reason was that it was necessary to start quickly and with limited human resources. At the beginning of any project, personnel is everything - when the cloud is formed, this is always a key issue. When time is short, it is very difficult to write something serious from scratch.
Technical Note
Neutron is integrated into OpenStack and has:
- many different networking options: Vlan, Overlay, Flat;
- a wide range of network functions: routers, load balancers, VPN, DNS, Firewall, BGP signaling;
- detailed and comprehensive documentation.
OpenStack Neutron has a simple architecture of:
- Neutron API, which accepts incoming user requests;
- ML2 plugin, which implements all the basic logic of Neutron;
- databases;
- RabbitMQ on the transport layer;
- agents involved in setting up the Data plane;
- Data plane, which can be OVS, NetNS, Daemons and others.
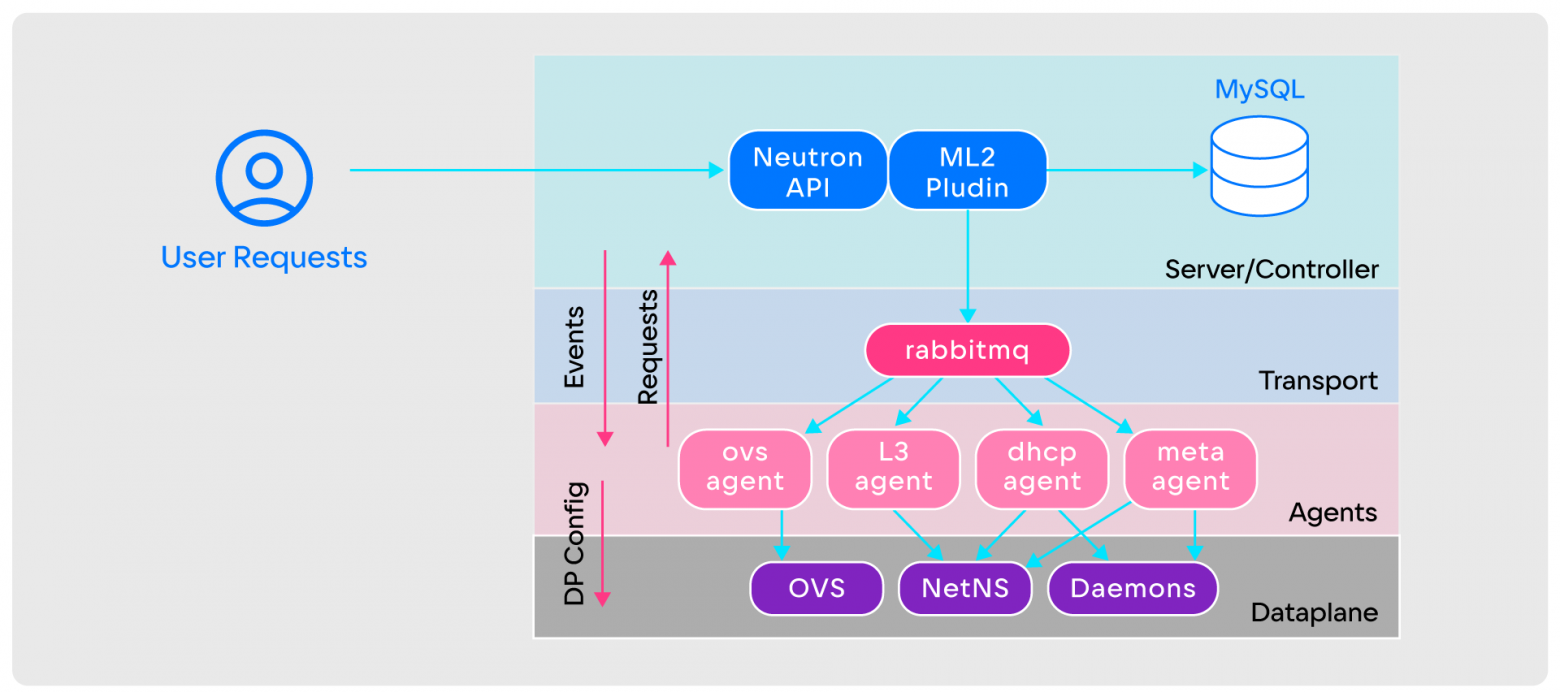
OpenStack Neutron works like this:
- To create a virtual network, the user makes a request to the Neutron API.
- The Neutron API passes the request to the ML2 plugin.
- The ML2 plugin sends network creation notifications to all agents via RabbitMQ.
- After receiving notifications, agents determine on which computing nodes the network is created. If there are nodes, they begin setting up the Data plane; if not, they ignore them.
The beginning of problems with operation at large volumes
A couple of years later, the team grew, the customer base increased, and along with this, some difficulties arose with Neutron - mostly operational, since there were no problems adding features. OpenStack Neutron itself is quite simple in terms of performance, but in practice, due to architectural features and the lack of initial adaptation to large volumes, failures often occur. Several of them are listed below, and it is worth clarifying that they become especially inconvenient when operating on cloud volumes.
Agents do not store state (stateless). They don’t remember the Data plane settings, there is no feedback on how exactly it was configured or whether it was configured at all. This creates difficulties. For example, an agent may miss some events due to a temporary shutdown, overload or workload of the node on which it is located. This is critical in the cloud, where the state of resources is constantly changing.
This problem is partially mitigated by the Full Sync mechanism. It allows the agent to request all information about its state from the server in case of any errors. But with hundreds of entities in a node, Full Sync can take several hours.
Overcomplicated Data plane. Typically, in a Neutron overlay configuration, the center of the entire Data plane is OVS. It is responsible for connecting virtual machines and connecting network functions: DHCP, DNS, Metadata Proxy and others. The OVS Agent is responsible for configuring OVS. Essentially, the logic of the entire network resides within OVS and the OVS Agent.
This complication makes it almost impossible to keep track of events. If several virtual machines are running on a node, OVS will have tens of thousands of rules that are difficult to understand. Even OVS tracing and monitoring does not always help with this.
Event-based communication via RabbitMQ. Agents communicate with the server using events. But there are errors in the code of all services - Neutron, agents, RabbitMQ. Because of this, agents can partially ignore events, and RabbitMQ can lose them during delivery due to different Race conditions. If it fails, the entire SDN will be unavailable and unmanageable. In addition, the scalability of RabbitMQ is limited: as the flow of events increases, some events may be lost. This leads to numerous problems. Gaps occur in the Data plane configuration and errors occur during traffic transmission. Monitoring these events is difficult.
More functionality - more events. OpenStack Neutron is configurable and allows you to enable many different functions. But this leads to an avalanche-like increase in the number of events from each of them. For example, Neutron with a simple Plane or VLAN configuration and basic services such as DHCP and Metadata Proxy can run reliably on 1000 hypervisors. But when overlay networks with a distributed routing mechanism, BGP signaling and other functions are enabled, problems appear already with 100 hypervisors.
Preliminary load testing helps prevent them. This must be done before enabling any additional functionality.
Architecture Limits. Mirantis itself says that 500 nodes is the limit and Neutron is not positioned as an infinitely scalable product that will withstand cloud scale.
Choosing between your own development and a ready-made solution
The reliability and stability of the cloud is directly related to the choice of solution. For some time, Neutron met the needs of VK Cloud, but then it stopped. An objective market analysis showed that adding features to some SDNs is easy, to others it’s difficult, and to others it’s very difficult.
Due to the lack of a worthy alternative, developing your own SDN has become a necessity.
When choosing an alternative SDN, only two options were considered:
- Move to another SDN: Tungsten Fabric/OpenContrail, OpenDayLight, OVN.
- Rework OpenStack Neutron.
The required SDN had several requirements:
- Support for the current set of networking features. Many functions that customers need have already been enabled. They cannot be disabled: the new solution must have the same functionality.
- DC network type “L3 to rack (ToR)”. In data centers, networks are built on the “L3 per rack” principle. Because of this, some fault tolerance protocols, such as VRRP, which rely on a single L2 broadcast domain between all servers, are not supported. In addition, external traffic needs to be signaled towards ToR over BGP.
- Scaling. The ability to scale or shard is needed to ensure network resiliency when bottlenecks are detected and make it easier to eliminate them.
- Seamless migration from current SDN. Moving to a new SDN should not affect client experience or functionality.
- Opportunity and potential for improvement. There was no ready-made solution “out of the box” for the stated requirements, so we only need Open-Source solutions that can be modified independently.
Based on the requirements, the choice was reduced to two options: Tungsten Fabric and the same OpenStack Neutron. But:
- U Tungsten Fabric there is no necessary functionality, it needs to be completed immediately. Refinement is complicated by a huge code base, which is difficult to understand due to the lack of publicly available documentation. An additional challenge is the large array of technologies. This complicates implementation, operation and support. As a result, the disadvantages of the solution outweigh the advantages of Tungsten Fabric - wide functionality and the ability to integrate into “L3 on a rack”.
- In processing OpenStack Neutron there are many advantages: the necessary functions are already there, migration is not needed, improvement can be carried out step by step, and the team has sufficient expertise. But the shortcomings of Neutron, which were listed above, do not go away - because of them, we were looking for an alternative SDN. In addition, reworking would require changing too much code and working with an inappropriate architecture.
Since both Tungsten Fabric and OpenStack Neutron only met part of the requirements, we decided to develop our own SDN.
How to write your own SDN and migrate the platform to it when everything works on the old one
There are two key disadvantages to writing your own solution:
- Writing SDN is difficult. We need a large team with expertise in the Control plane and Data plane and knowledge of networks.
- Great Time-to-market. It takes a lot of time to get a ready-made solution and put it into operation.
But there are more advantages, and they are more significant:
- You can make any architecture without additional unnecessary elements.
- Any migration can be envisaged.
- You can solve a problem that is interesting for developers.
After weighing the pros and cons, the VK Cloud team began developing their SDN. They called her Sprut. It took less than a year to develop. Of course, now Sprut does not yet have all the functionality, but it is already in production together with Neutron.
What's important is that Sprut doesn't have the same problems as Neutron. For this purpose, its architecture was completely redesigned:
- Agents have the ability to continuously collect information about Data plane settings.
- There is no longer an event-based model of communication between components. Agents now always receive the target state they should be in from the server and continually re-query it. The result is an analogue of permanent Full Sync, in which agents compare the current state of the Data plane with the target state from the server, apply the necessary diff to the Data plane and bring it to the current state. In automatic control theory, this approach is called a closed control loop.
- RabbitMQ has been replaced by the regular HTTP REST API. It copes better with large amounts of data on the target state of agents, and is easier to develop and monitor.
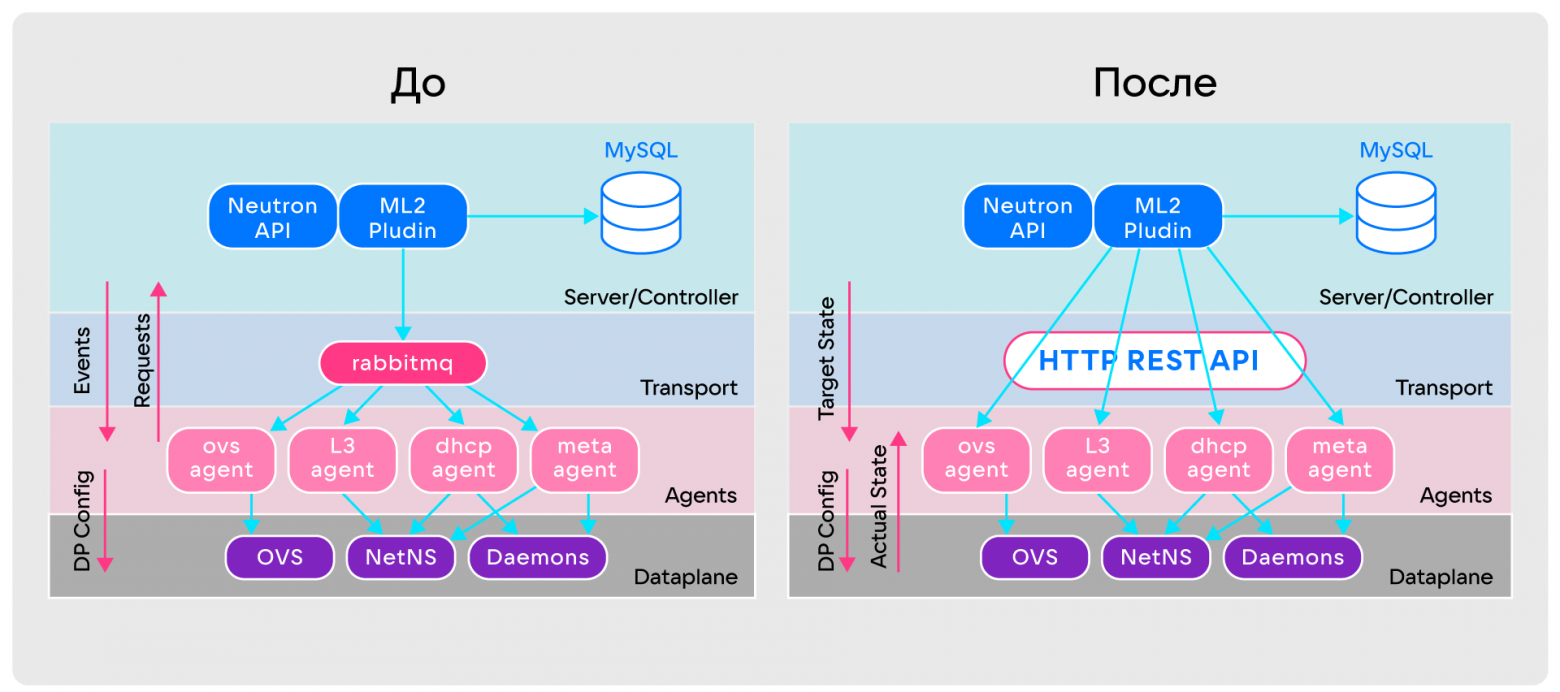 Comparison of OpenStack Neutron and SPRUT architectures
Comparison of OpenStack Neutron and SPRUT architecturesBut these alterations did not solve the main problem - the Data plane remained complex. To understand how to simplify it, I had to delve into the theory and analyze the basic virtual primitives of Neutron: port, network, subnet, router.
It is easy to understand the principle of operation of a cloud network if you project the components of a virtual network onto a familiar physical one.
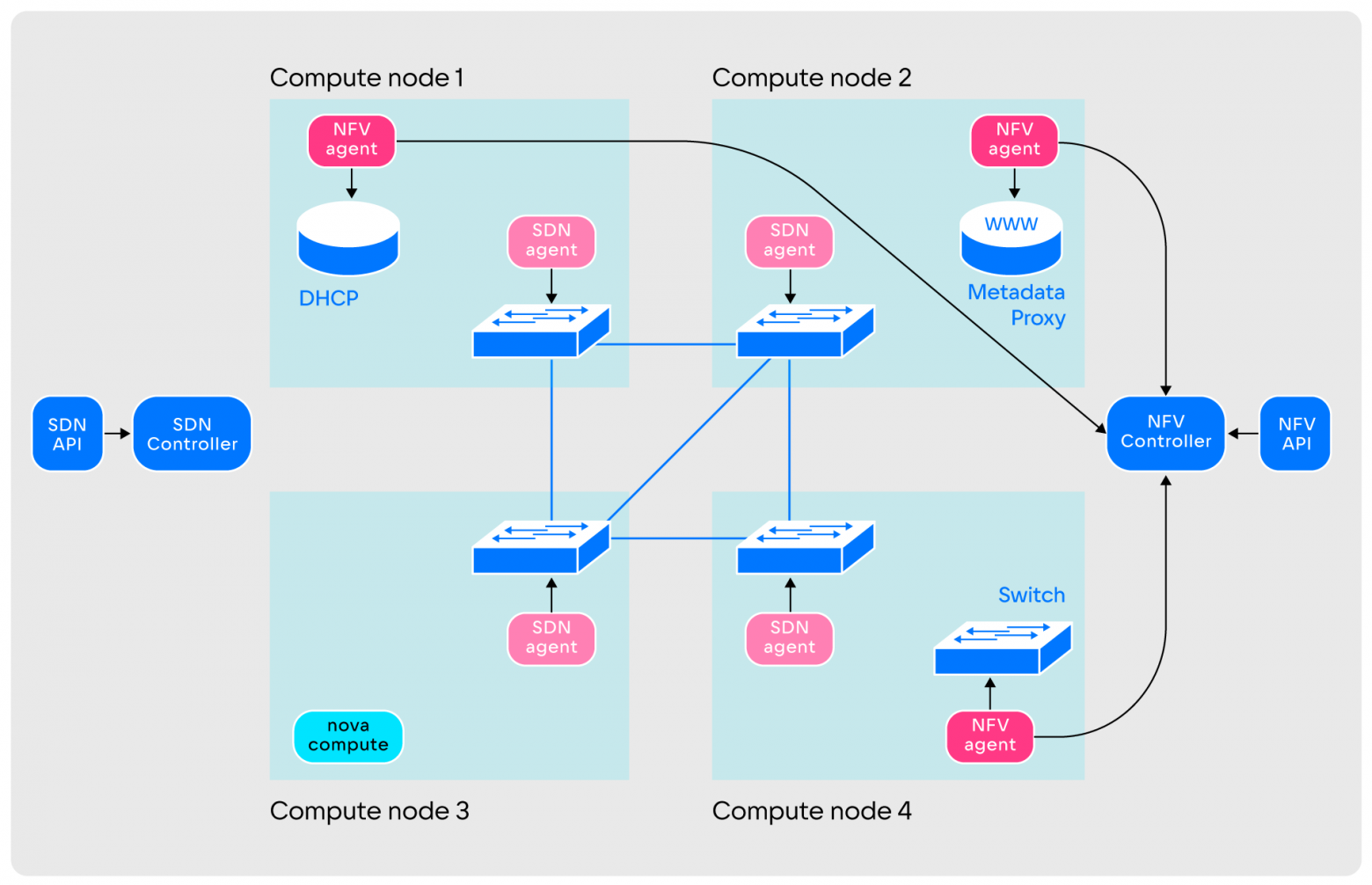
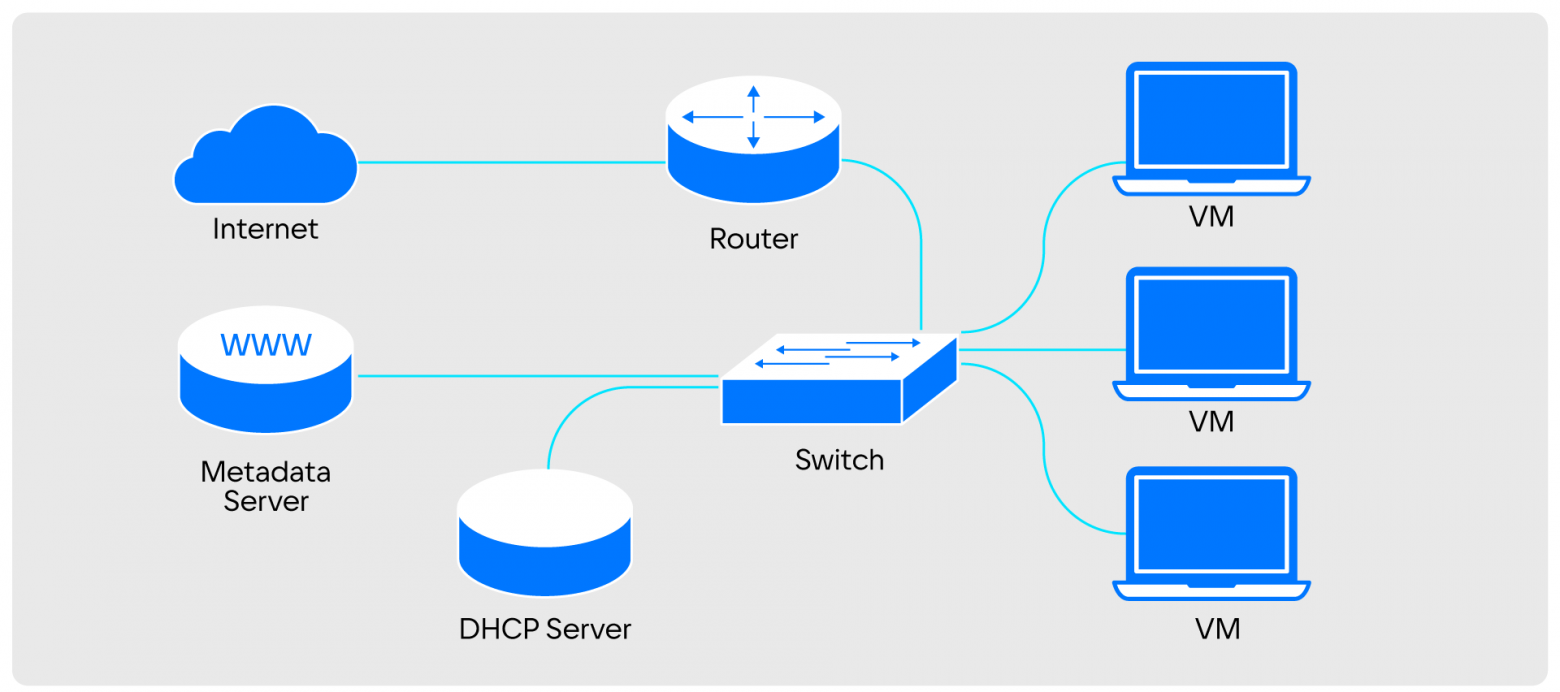 The virtual network turns into a Switch and a Metadata Proxy. The virtual subnet turns into a DHCP server. The virtual router becomes physical. Ports become regular or virtual machines
The virtual network turns into a Switch and a Metadata Proxy. The virtual subnet turns into a DHCP server. The virtual router becomes physical. Ports become regular or virtual machinesIn a physical infrastructure format, all these components are distributed across a huge cluster of physical nodes that are interconnected. To do this, the components are connected by a set of switches.
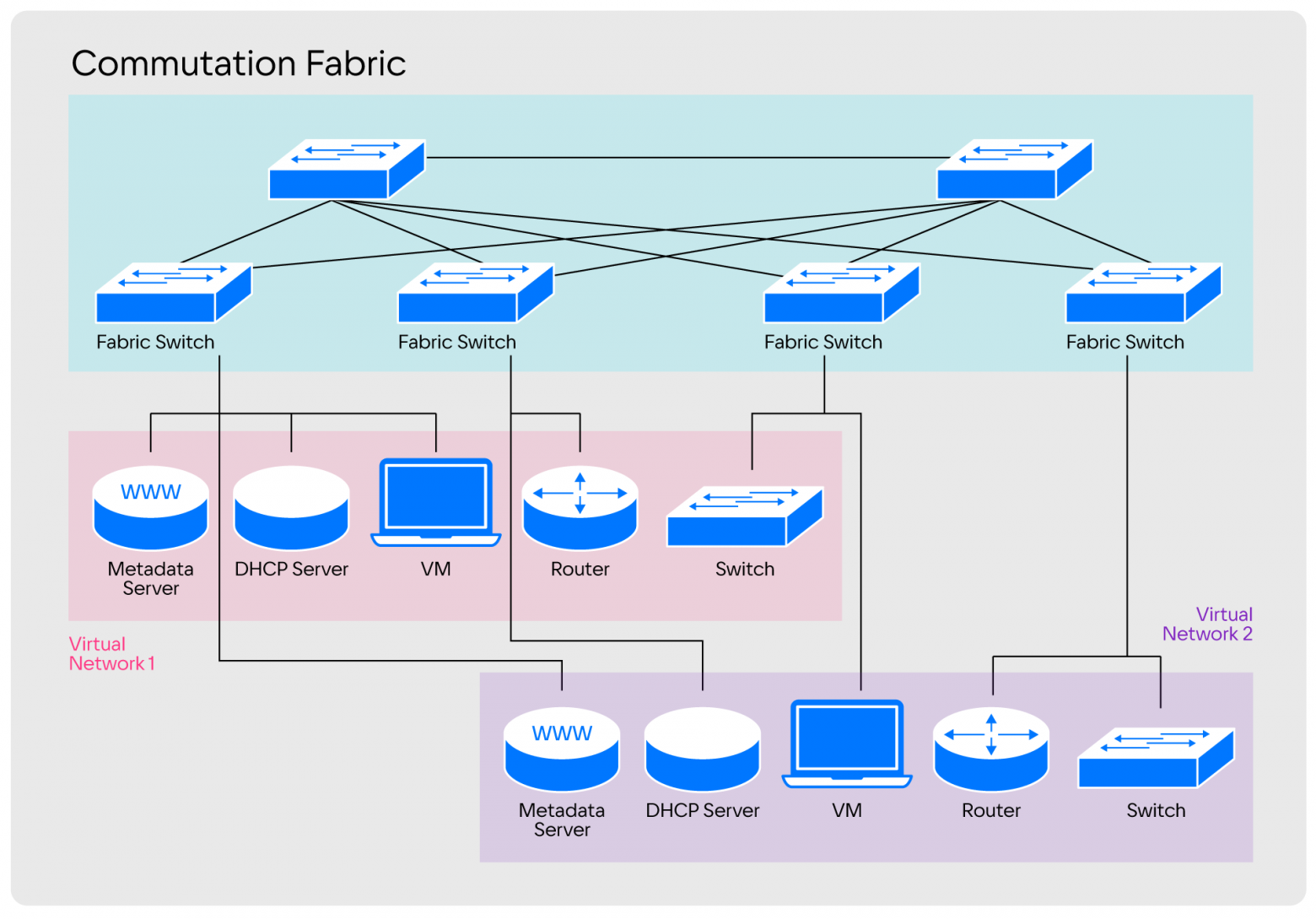
Segmentation among these switches occurs using VLAN technology or the more modern MPLS. In this case, all segments represent different virtual networks.
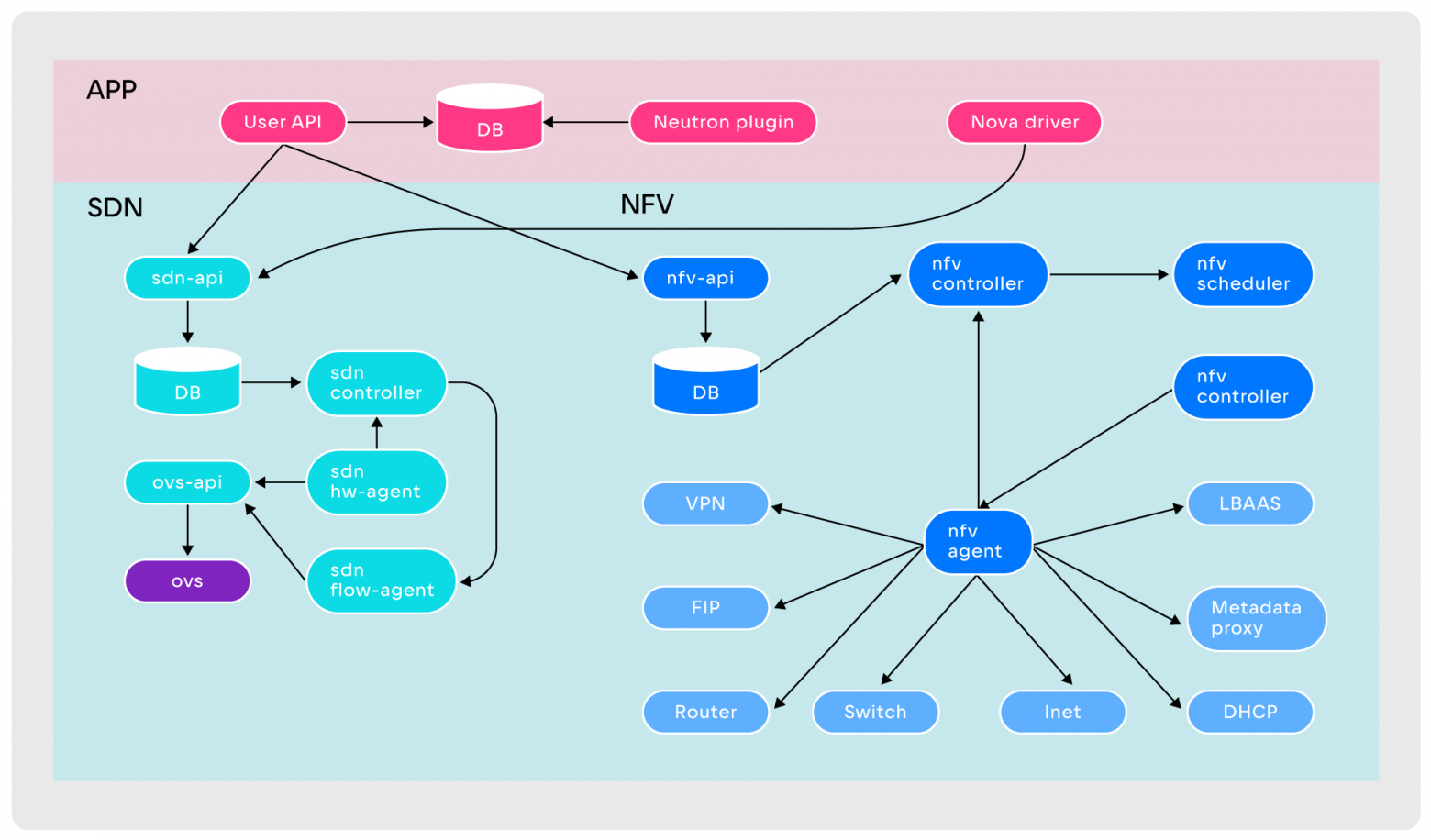
The division that is used in standard networks fully meets our operational needs, so when designing SPRUT, we similarly divided the areas of responsibility into three levels: NFV, SDN and APP.
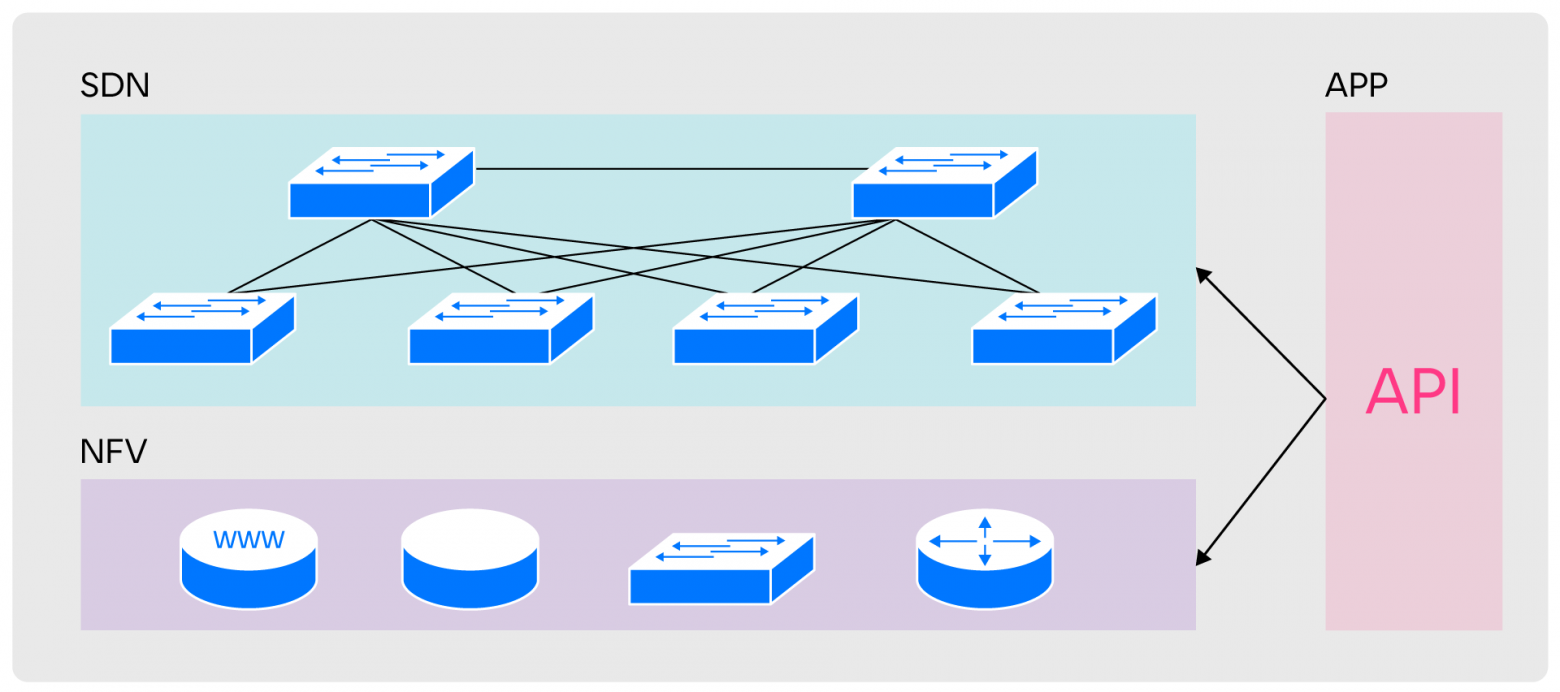
NFV (Network Function Virtualization) is responsible for providing network entities, SDN is responsible for their communication with each other. APP ensures API level compatibility
Separating responsibilities helped us simplify the Data plane in the original SPRUT architecture.
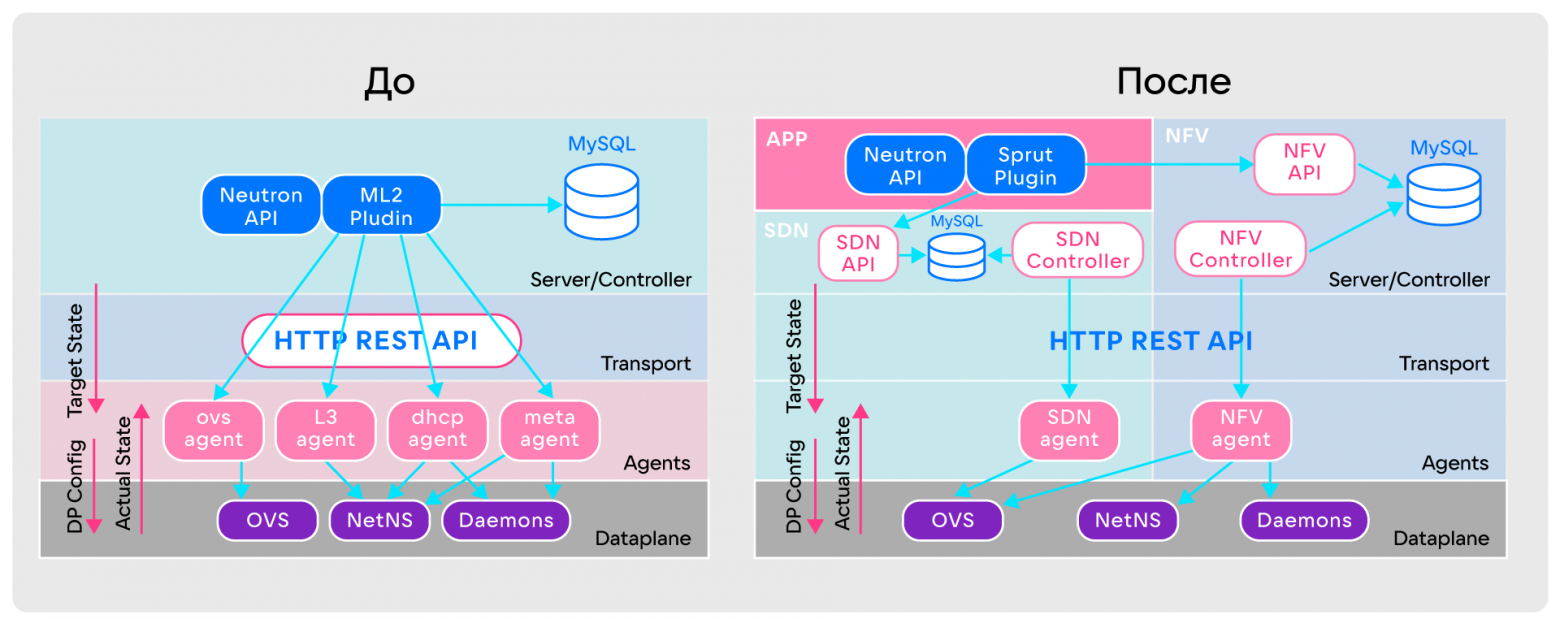
After making changes, two independent layers appeared in the architecture, each with its own agents, controllers, databases and APIs. Levels work with their own primitives and are independent of each other. The connection between the levels is provided by Application (APP).
This modernization simplified the development of the Control plane and helped to natively get rid of the problems characteristic of Neutron. In SPRUT:
- agents receive information about Data plane settings;
- events are not lost due to abandoning the event model;
- Data plane is easier and more flexible to configure.
Technical information
Arrangement of SPRUT architectural layers
In the SPRUT architecture, each layer has its own characteristics.
SDN. The layer consists of SDN agents running on computing nodes, an SDN controller and an SDN API. The interaction occurs as follows:
- After launch, the agents create virtual switches on their hosts and connect them to each other with tunnels
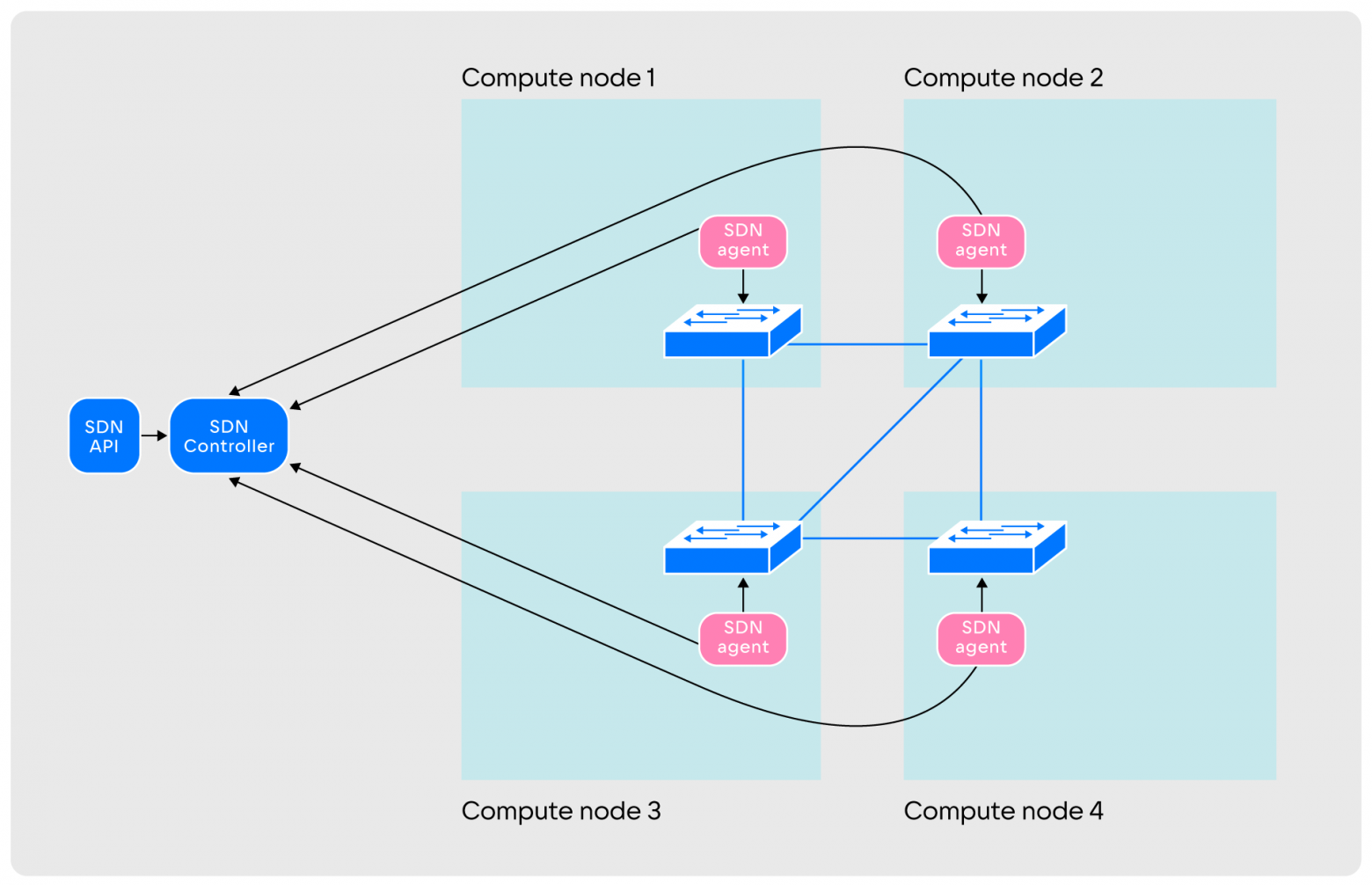 Tunnels can have any configuration: full connectivity, partial, separated regions or another.
Tunnels can have any configuration: full connectivity, partial, separated regions or another. - After creating tunnels, agents report this to the controller. At the same time, agents monitor the tunnels, sending data packets through them. Information about the state of the tunnels in real time is transmitted to the controller, which builds a network graph.
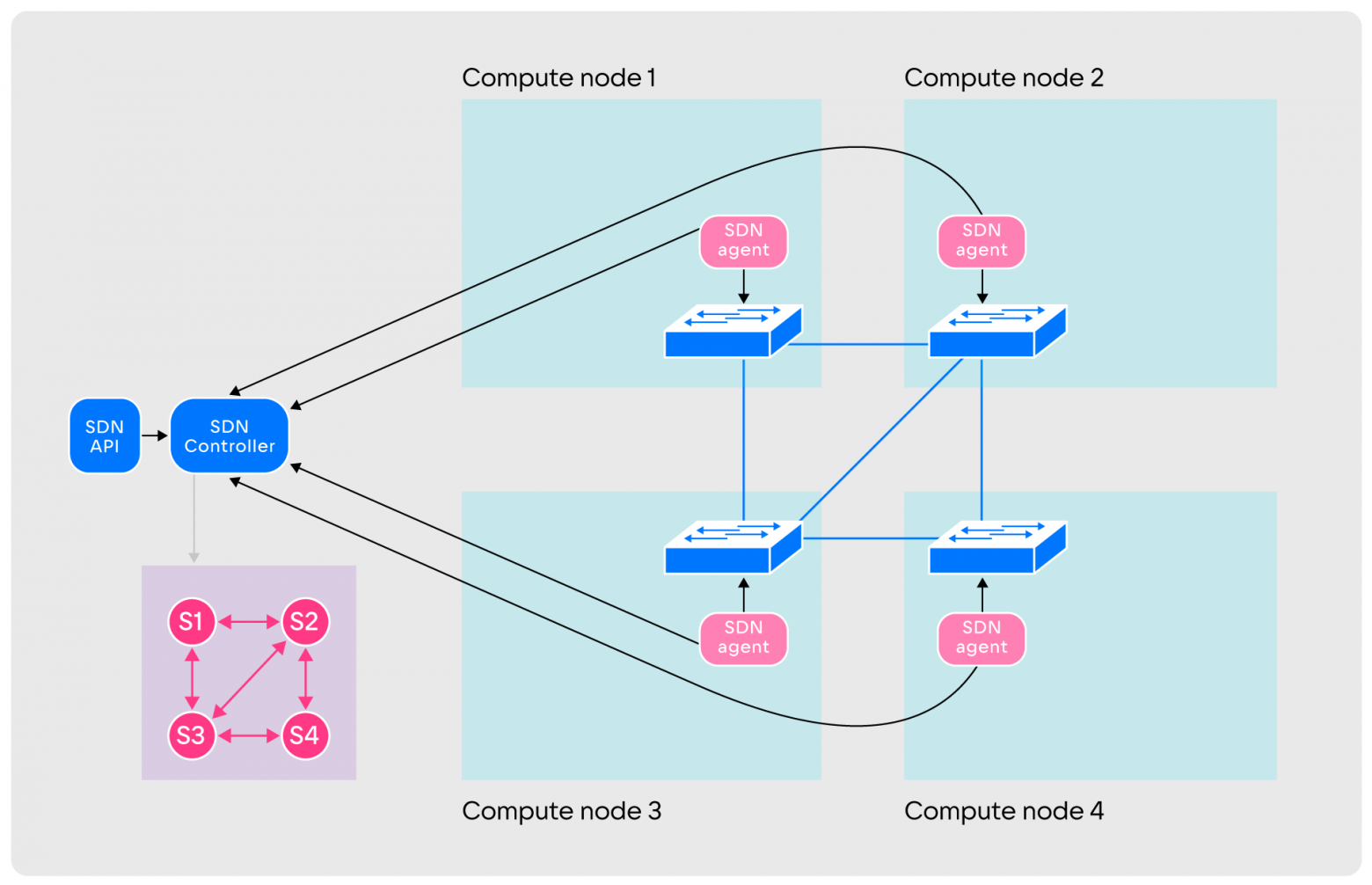 The vertices of the graph are switches, the edges are constructed tunnels. The graph is constantly updated taking into account current information
The vertices of the graph are switches, the edges are constructed tunnels. The graph is constantly updated taking into account current information - After this, SDN is ready to create primitives. It works with two: Link and Endpoint. Link is an entity connecting two Endpoints. Endpoint - connection point to a system of switches. Only one Link connects to one Endpoint, and a Link connects no more than two Endpoints.
- When creating a connection between nodes, two Endpoints are launched on them via the API. The addition of events to the API and database begins. Then a Link is built between the Endpoint, after which the controller determines the shortest path for transmitting traffic from one node to the second. To do this, it uses a network graph and Dijkstra's algorithm.
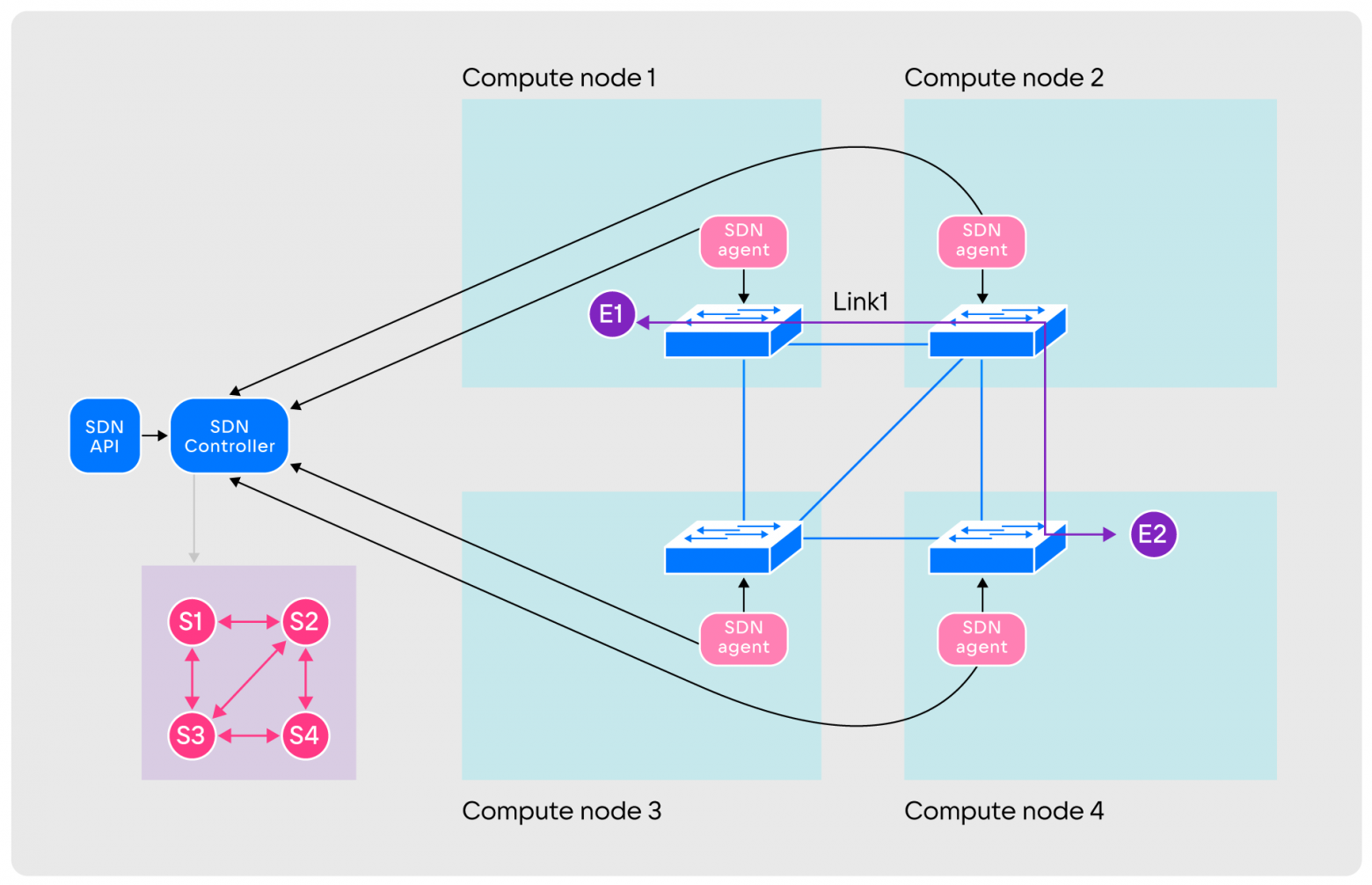
All switches on the selected route receive traffic rules indicating the sequence of ports. Subsequently, the rules are loaded into agents, which build a route on real switches. In part, this scheme resembles the operation of the OSPF routing protocol.
This interaction format ensures speed and eliminates errors during traffic transmission. But SDN is not the only layer in SPRUT, because using Link and Endpoint you can only connect two virtual machines. This is not enough to create a full-fledged virtual network - you need network entities for which the NFV layer is responsible.
NFV layer device. The design of the NFV layer is somewhat similar to SDN:
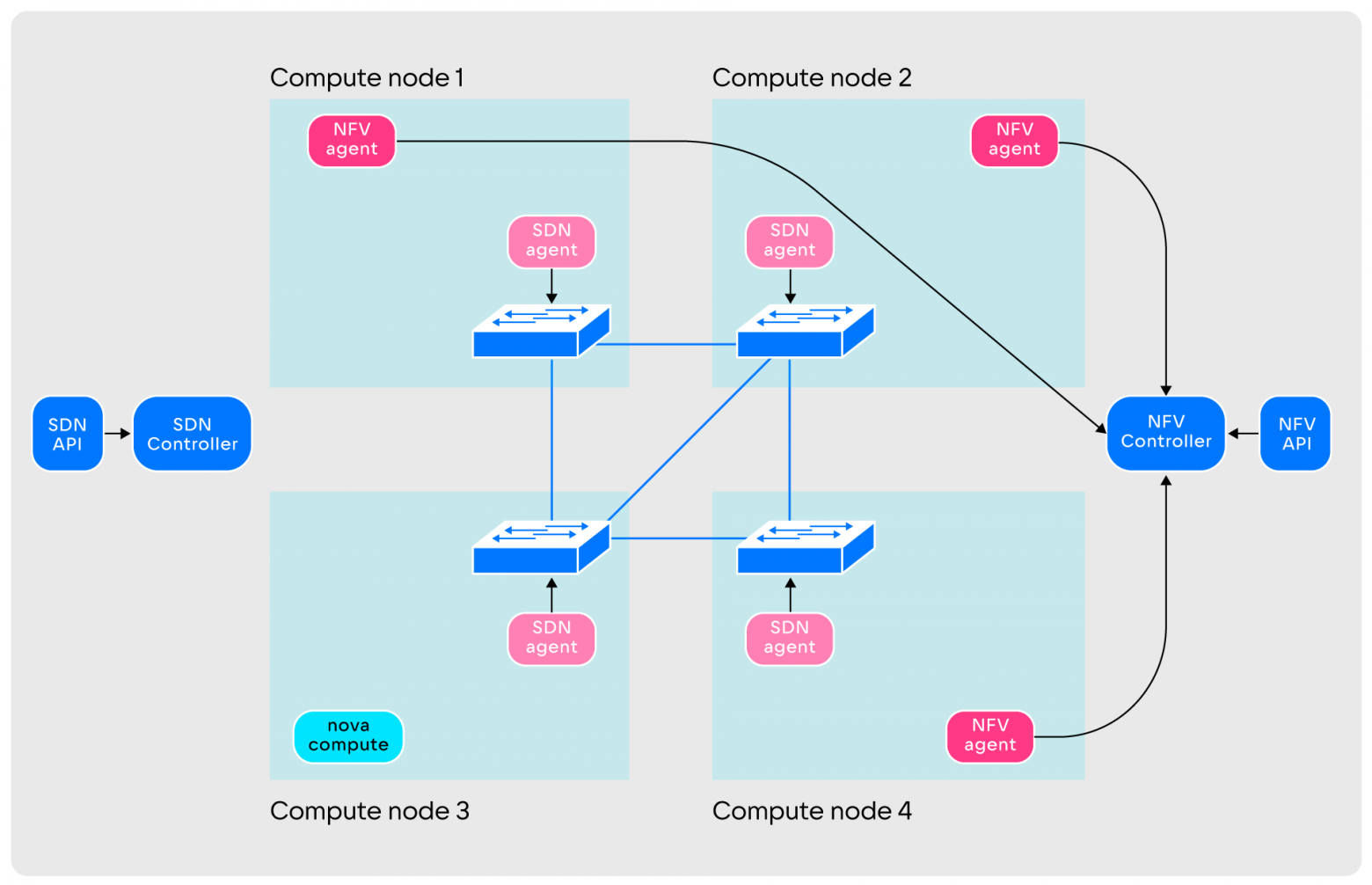
NFV-level agents may not be located on all nodes, but only on those selected by the operations team: this helps save network resources of virtual machines. The NFV layer operates DHCP, Switch, Router, Metadata Proxy and other primitives, the number of functions is constantly increasing. The level components interact as follows:
- When launched, NFV agents create the number of entities determined by the operation command.
 Entities are created empty and not used by anyone
Entities are created empty and not used by anyone - Agents transmit information to the controller. After this, the layer is ready to serve user requests.
The principle of joint operation of the SDN and NFV layers
In practice, creating a virtual network using SPRUT occurs as follows:
- A user who wants to create a virtual network makes a request to the Application layer.
- The Application layer redirects received requests and transforms them into a set of entities of the SDN and NFV layers.
- Unused entities are taken from the NFV layer and connected to each other using Link and Endpoint. This network is still missing only virtual machines.
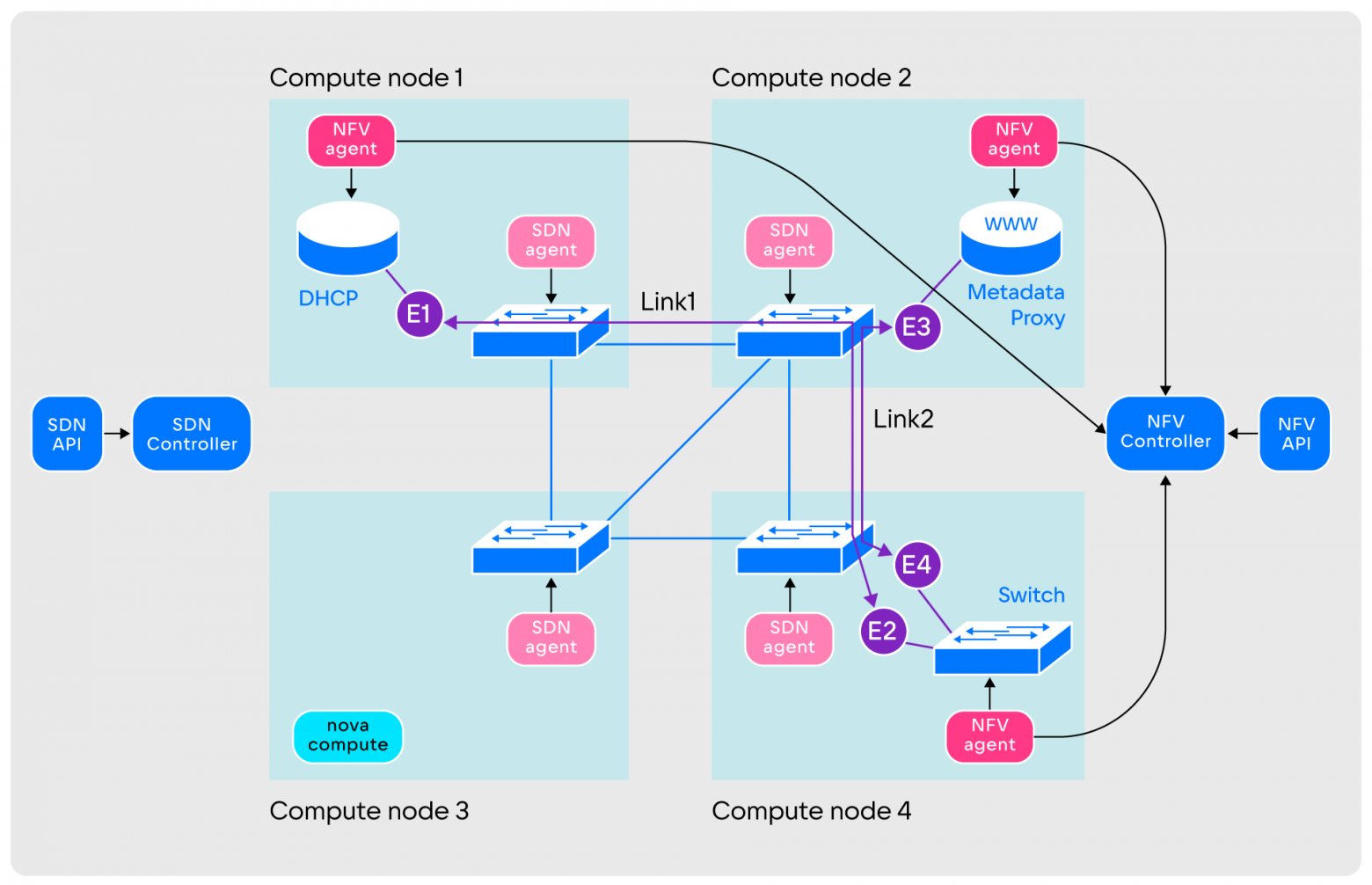
- Next, the user accesses the OpenStack service, which is responsible for virtual machines. The user's request reaches the Nova-compute agent, which starts the QEMU process.
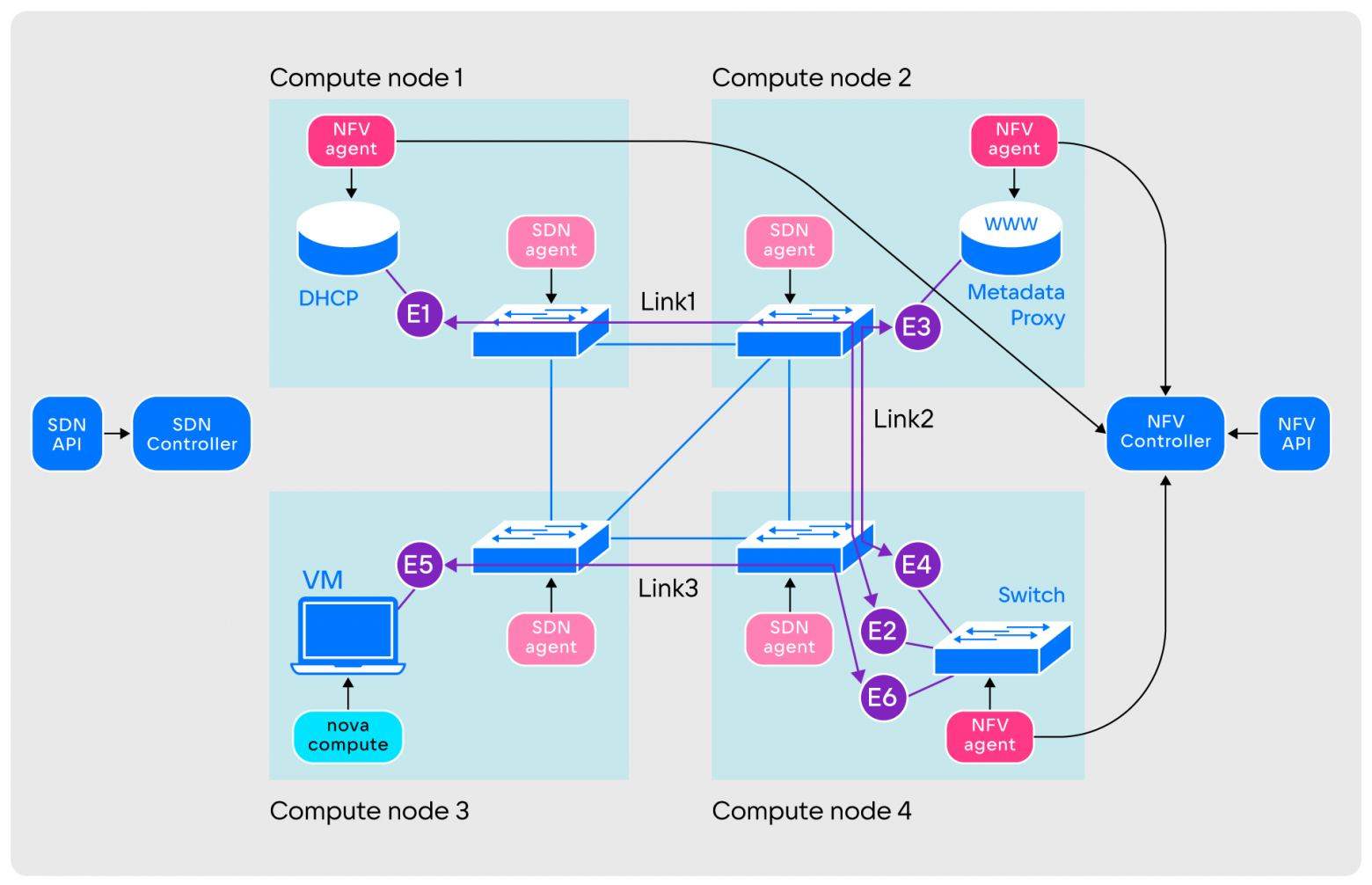
- Simultaneously with the launch of QEMU, the Nova-compute agent contacts the Application layer to connect the virtual machine to the network. In response to this, the Application layer creates a set of Links and Endpoints to connect the virtual machine to the switch. This completes the creation of a virtual network.
In its full version, the SPRUT circuit is more extensive and includes more components:
 General diagram of SPRUT components. We do not list all of them, so that the article does not become completely astronomical in size; we touch only on the most important
General diagram of SPRUT components. We do not list all of them, so that the article does not become completely astronomical in size; we touch only on the most importantThe Application layer in SPRUT is a custom plugin for Neutron that replaces the ML2 plugin. It is responsible for converting Neutron entities into the required components. Other SDNs use a similar approach. In addition, for stable work with Nova, Sprut provides a Nova Driver.
History of SDN development in VK Cloud: today and plans for tomorrow
August 22, 2023 marks the 10th anniversary of one of the most successful SDNs in history - OpenDaylight. Over the years, developers and architects have improved scalability, thrown out a lot of Legacy code, and then plan to deal with compatibility: a lot has been done, and now we need to make sure that they will not interfere with each other.
It also became obvious that the transition to a modular microservice architecture is a step that needs to be taken for the development of the product. Microservice architecture allows you to be more flexible with hosting tools, such as containerization. The result is scalability, manageability and the ability to reduce the connectivity of components.
Our Sprut is younger. We are very pleased that we were able not only to take advantage of the work of our comrades from the industry, but also to improve the product. As a result, Sprut received a number of important features, including:
- microservice architecture,
- OpenVSwitch as Data plane,
- integration with Nova and Neutron,
- implementation and use of a closed control loop,
- small code base - about 15,000 lines.
What’s important is that development to production took less than a year. In the future, we plan to add to the product and will definitely tell you what we got.
The Highload++ conference will be held in Moscow on November 27–28. SDN Sprut developers will speak at it report, in which they will talk about the implementation of EVPN in VK Cloud and the problems of vendor solutions.
Why This Matters In Practice
Beyond the original publication, As we wrote at VK Cloud SDN matters because teams need reusable decision patterns, not one-off anecdotes. With the advent of broadband access and high speeds of mobile Internet, network load has become one of the key bottlenecks for system perfor...
Operational Takeaways
- Separate core principles from context-specific details before implementation.
- Define measurable success criteria before adopting the approach.
- Validate assumptions on a small scope, then scale based on evidence.
Quick Applicability Checklist
- Can this be reproduced with your current team and constraints?
- Do you have observable signals to confirm improvement?
- What trade-off (speed, cost, complexity, risk) are you accepting?
FAQ
What is this article about in one sentence?
This article explains the core idea in practical terms and focuses on what you can apply in real work.
Who is this article for?
It is written for engineers, technical leaders, and curious readers who want a clear, implementation-focused explanation.
What should I read next?
Use the related articles below to continue with closely connected topics and concrete examples.





